Things I learned when building an API gateway with reactive Spring
Coming from a non-reactive and more traditional Java Spring API background, I had limited experience working with Mono and Flux. To build our Spring Cloud Gateway application, I needed to bring myself up to speed on these concepts. I hope this blog post may help others who wish to learn more about how we can use reactive streams with Spring.
Mono and Flux are part of the Spring WebFlux library. They are Spring’s implementation of reactive streams.
If you are familiar with the standard Streams API added in Java 8 then you can think of Reactive Streams as Java Streams with
the added element of time. Normally data in a Stream is available all at once but with Reactive Streams, you are
processing the data as it is produced by a source. For example, the source could be a database query. As the records
are returned from the database, they are sent down your reactive stream.
If you’ve never heard of Streams before, you can think of them as a conveyor belt on an assembly line. You can alter items as they come down the belt. A caveat of this is that items may or may not ever be sent down the conveyor belt. An important thing to note is that code involving reactive streams is not executed unless something subscribes to that stream.
A Flux is a Reactive Stream that can contain any number of elements of the same type. It may have 0 or infinite
values pass through it.
A Mono is a Reactive Stream that contains either 0 or 1 value of the same type. It may have 0 or 1 value pass
through it.
Why use reactive streams?
Now that we are comfortable with what reactive streams are, it begs the question, why should I use them? Why did I bother to write this post?
The key reason boils down to that element of time I mentioned earlier. In a traditional model, processes are run on a thread. When that process performs a blocking operation, the thread has to wait for that to complete. This may only take a few tens of milliseconds but, if you take into consideration how fast modern computers are, this is a big missed opportunity to process data. To use a rather contrived example, the CPU from an IPhone 13 has a max clock speed of 3.23GHz. Meaning that the IPhone can make up to 3,230,000,000 decisions a second (or 3,230,000 decisions per millisecond). Instead, it’s waiting around for your operation to complete. Think of all that time wasted!
Now a computer typically solves this by spinning up a new thread and passing the next request to that new thread. This allows operations to keep being processed whilst we wait for the original thread to free up again. It does however come with a cost as creating/destroying threads is very costly in terms of time and processing power. This would cause the system to slow down as we spin up more threads to handle the incoming requests. A caveat here is that a system can only create a certain amount of threads, once this limit has been reached, it will be stuck waiting for threads to come free.
Reactive programming works differently. In this model, whenever a task requires a blocking operation to be run, an event will be fired down the stream when the task has returned a result. Meanwhile, the thread pool can continue handling events on other streams. Then by the time our blocking operation returns a result, our system has been keeping busy handling other events in other streams. By handling operations like this, a system can maintain an incredibly high throughput.
Our scenario seemed a perfect fit for use of the reactive model. We wanted to create an API gateway that would be handling roughly 300 requests per second and all of that involved sending another request downstream and waiting for a response. Making use of a non-blocking reactive architecture means that we can handle this load with a small number of threads (and in turn fewer servers).
Example usages
Returning an array of constants
A simple example of how we can use reactive streams in our application would be an endpoint to return some constants. Below
I have included an example controller which returns an array of constants as a Flux. The only difference between this
endpoint and a regular Spring endpoint is that the return type is still wrapped in a Flux. Spring will automatically
unwrap this into an array of strings.
package com.example.webfluxdemo.controller;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/api/constants")
public class ConstantsController {
@GetMapping(produces = MediaType.APPLICATION_JSON_VALUE)
public Flux<String> getValues() {
return Flux.just("Value-1", "Value-2", "Value-3");
}
}
Fetching a single database record
One way in which you could use Mono is to fetch a single value from a database and return it to a client. This
could be done by using reactive database drivers and returning a Mono datatype in your controller method. To do
this in a reactive/non-blocking way, your value must be wrapped in a Mono/Flux through the whole stack from
your database call to your controller method.
@GetMapping(path = "user", produces = APPLICATION_JSON_VALUE)
public Mono<UserRepresentation> getUser() {
return userService.getUser()
.map(user -> new UserRepresentation(user.userId(), String.format("%s %s", user.firstName(), user.lastName())));
}
public Mono<User> getUser() {
return userRepository.findById("1").map(UserEntity::toDomain);
}
@Repository
public interface UserRepository extends ReactiveCrudRepository<UserEntity, String> {
}
Fetching multiple database records
A Flux can be used in a very similar way to a Mono however it can bring back multiple values as opposed to one.
It would also push values to the client as they arrive as opposed to waiting for all values before returning the
response.
Below I have included an example endpoint which fetches all the records from a document in a Mongo database.
Using the Spring Data library we can easily make reactive calls to the database and return a stream of results
in the form of a Flux. These can be passed through to the controller and returned to the client.
@GetMapping(path = "users", produces = APPLICATION_JSON_VALUE)
public Flux<UserRepresentation> getUsers() {
return userService.getUsers()
.filter(user -> (user.firstName().toUpperCase().startsWith("J")))
.map(user -> new UserRepresentation(user.userId(), String.format("%s %s", user.firstName(), user.lastName())));
}
public Flux<User> getUsers() {
return userRepository.findAll().map(UserEntity::toDomain);
}
@Repository
public interface UserRepository extends ReactiveCrudRepository<UserEntity, String> {
}
Some of you may be thinking “if the database is streaming the records out as they are found by the query, why does the app
have to return them all at once to the client?”. To that question, I present you with this MediaType.APPLICATION_NDJSON_VALUE (newline
delimited json). Notice we have been returning our results in the form of MediaType.APPLICATION_JSON_VALUE which is just plain old
JSON. Newline delimited json allows whole json objects to be returned separated by newlines like so:
{"id": "1", "name": "item-1"}
{"id": "2", "name": "item-2"}
{"id": "3", "name": "item-3"}
By making a simple change to our endpoint, we can return our records as they come back from the DB, as opposed to waiting for all of them before returning.
@GetMapping(path = "users", produces = APPLICATION_NDJSON_VALUE)
public Flux<UserRepresentation> getUsers() {
return userService.getUsers()
.filter(user -> (user.firstName().toUpperCase().startsWith("J")))
.map(user -> new UserRepresentation(user.userId(), String.format("%s %s", user.firstName(), user.lastName())));
}
Hitting this endpoint demonstrates the power of using reactive streams in your application, especially if your client was also using reactive streams. Instead of having to wait for all the data to be fetched and processed before you get a result, you can be working through each record as it is returned.
To illustrate this, I delayed all the elements in the Flux slightly and sent a cURL request to the endpoint via
terminal:
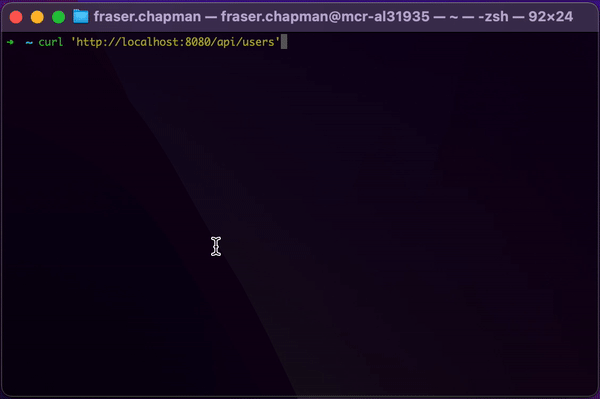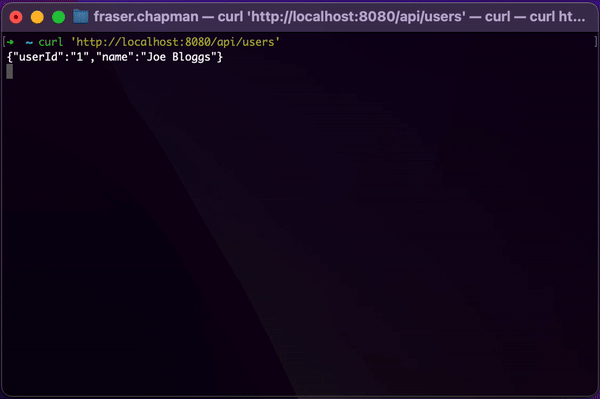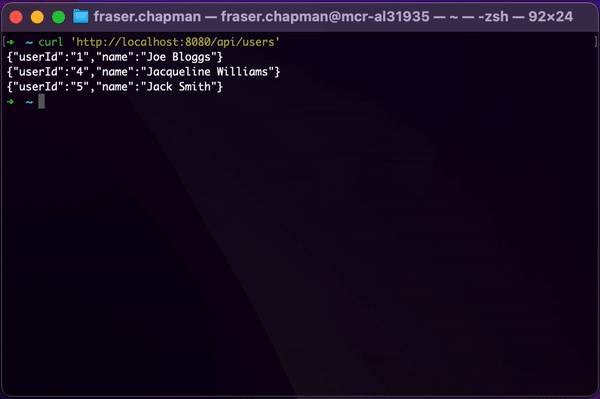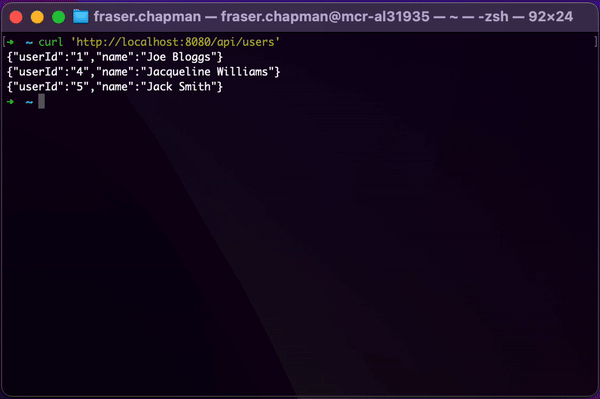
How we made use of Reactive Streams
As Reactive Streams have the added element of time, they can be particularly useful in writing non-blocking code. Our use case for them is in our API gateway. Since our API gateway will need to be able to handle high levels of throughput, we need to write our code as non-blocking as possible. Using Spring Cloud Gateway, we can get an entirely reactive/non-blocking API gateway out of the box.
Our API gateway needs to do a little more than act as a reverse proxy between us and the outside world. There are scenarios in which we want to send network requests to other apps before forwarding the client request downstream. To do this in a non-blocking way, we need to take advantage of Spring’s new HTTP client WebClient. In our use case, we need to send a request to one of our microservices and so long as we get a successful HTTP status code with the response, we can allow the client to continue with their journey.
Repository Layer
When making a network call with WebClient, you have to think of your code as more of a specification of how you want WebClient to send a request and what it should do with
the response. It follows that same Stream-like API pattern.
In our repository method, we configure WebClient to send a POST request to a url with some headers. We then call the retrieve() method. This then allows us to
configure how we want WebClient to handle our response if and when we get one. bodyToMono(ResponsePayload.class) allows us to configure how we want WebClient to
map our response. In this case, we are mapping our response to a Mono<User>.
@Override
public Mono<User> validate(final String userToken) {
final String url = String.format("%s/user", config.getRoot());
return webClient.post()
.uri(url)
.header(AUTHORIZATION, config.getAuth())
.header(tokenHeader, userToken)
.retrieve()
.onStatus(HttpStatus::is4xxClientError, response -> Mono.error(new BadRequestException("helpful message")))
.onStatus(HttpStatus::is5xxServerError, ClientResponse::createException)
.bodyToMono(User.class);
}
Service Layer
Our service class calls this repository method to fetch the information and simply returns it without performing any logic.
public Mono<User> validate(final String userToken) {
return repository.validate(userToken);
}
The Auth Token Service
Since the information we have fetched is used widely across our gateway filters, we created a AuthTokenService class to handle the storing of
this information in a request-scoped way, similar to ThreadLocal. The AuthTokenService exists to provide the caller with
user identity information.
When dealing with an incoming request in Spring Cloud Gateway, spring provides us with a ServerWebExchange variable, aptly named exchange in
this case. This exchange variable represents the whole interaction (or rather the exchange) between our gateway, the client, and downstream services.
It stores both the request sent by the client and the response we are returning to them. It also has an attributes field
of type Map<String, Object> that we can use to store request/exchange scoped data.
We pass in our exchange to the appendValidatedUserPayload() method, and we get back a Mono<ServerWebExchange> containing our exchange
with the requested information stored in the attributes map. This allows us to store information about the user and make it
accessible to all our filters which may be running without filters having to run in a specific order. Previous to this solution,
a filter would run first to hydrate the exchange with this information.
public Mono<ServerWebExchange> appendValidatedUserPayload(final ServerWebExchange exchange) {
return getValidatedUserPayload(exchange).map(userAuthenticationResult -> setValidatedUserPayload(exchange, userAuthenticationResult));
}
public Mono<UserAuthenticationResult> getValidatedUserPayload(final ServerWebExchange exchange) {
final ServerHttpRequest request = exchange.getRequest();
final Object preValidatedToken = exchange.getAttribute(JW_TOKEN);
if (nonNull(preValidatedToken)) {
return Mono.just(preValidatedToken)
.map(attribute -> (UserAuthenticationResult) attribute);
}
final String authToken = getBearerToken(request).orElseThrow(() ->new MissingJwTokenException("User has not provided an auth token"));
return authenticationService.validate(authToken);
}
private Optional<String> getBearerToken(final ServerHttpRequest request) {
final String authHeader = request.getHeaders().getFirst(AUTHORIZATION);
return nonNull(authHeader) ? Optional.of(authHeader.split(" ")[1]) : Optional.empty();
}
Filter Layer
All of this eventually leads back to our filter. In this scenario, we are only interested if that fetching of information has gone smoothly, if not, we will stop the request from going any further and return an appropriate response.
@Override
public GatewayFilter apply(final Config config) {
return new OrderedGatewayFilter((exchange, chain) ->
authTokenService.appendValidatedUserPayload(exchange)
.flatMap(validatedToken -> continueRequest(exchange, chain))
.onErrorResume(JwTokenValidationException.class, error -> unauthorised(exchange))
.onErrorResume(MissingJwTokenException.class, error -> unauthorised(exchange))
.onErrorResume(WebClientException.class, error -> {
LOG.error("Failed to validate auth token!", error);
return badGateway(exchange);
})
.onErrorResume(DecodingException.class, error -> {
LOG.error("Error decoding jwt token payload.", error);
return badRequest(exchange, chain);
}),
JWT_TOKEN_VALIDATION_FILTER_ORDER);
}
public static Mono<Void> unauthorised(final ServerWebExchange exchange) {
return respondWithError(exchange, UNAUTHORIZED);
}
public static Mono<Void> badGateway(final ServerWebExchange exchange) {
return respondWithError(exchange, BAD_GATEWAY);
}
public static Mono<Void> badRequest(final ServerWebExchange exchange) {
return respondWithError(exchange, BAD_REQUEST);
}
public static Mono<Void> continueRequest(final ServerWebExchange exchange, final GatewayFilterChain chain) {
return chain.filter(exchange);
}
Summary
I set out writing this post to help spread some of the knowledge I have picked up whilst working in this paradigm. Hopefully I have been successful in doing so and you have been able to take something away from this.
Spring is widely used throughout the industry at the minute and has earned itself a good reputation (at least within Auto Trader). We are comfortable using it and hoped their implementation of a reverse proxy with Spring Cloud Gateway would be really well put together. For most intents and purposes, it is! You can easily spin up a super simple gateway in no time at all, and you can build some complicated functionality on top of it too. There are plenty of pre-made filters and predicates to allow you to easily configure routes and manipulate requests/responses. You can also trust that it will be maintained well over the coming years by VMware.
Now that the project has come to a close and I have had time to reflect on the system we built, there are many learnings which I have been able to take away from it. Working with new tech is great! We got to build a system which is integral to the business and watch it power through requests like nobody’s business. We also had the pain of having to learn how it all works and how to use the libraries whenever we wanted to do something more complex. I found that parts of the documentation were lacking and I had to read through source code and Stack Overflow threads in order to figure out how to use certain functionality. Some of the classes we use seem to still be in development and could change at any moment. Most basic implementation is easy enough to use and is documented fairly well.
I have found that whilst this feels like a step forward technologically, it doesn’t always feel like the easiest thing to work with. Granted, I am not the most knowledgeable on this topic, and I think that there is still lots for me to learn about writing code in this paradigm/style. But that lends itself to the point I’m about to make that it’s such a different way of working, lots of time needs to be allowed to learn about it. The documentation could also be better to help facilitate this (explaining my motivation for this post). Fortunately for me, I was afforded the time to learn, and I was able to enjoy doing it because of this. I imagine other developers with more pressing time constraints would become frustrated.
Enjoyed that? Read some other posts.
Related Posts
25 Oct 2024—David Davies

In Part 1, I introduced JGit and its basic concepts for working with Git in Java. We covered how to clone a repository, make some changes to it, stage those changes,...
23 Oct 2024—David Davies

Have you ever wanted to work with Git in Java? Did you know there’s a library for that? It’s called JGit!
I recently had to work with a Git repository that is hosted...
