Auto Trader Engineering Blog
-
Wait, it's all histograms? Simplifying our Bayesian A/B testing methodology - Part 2

Image source: Wikimedia Commons.
The Bayesian approach to A/B testing has many advantages over a Frequentist approach. However, there are some drawbacks. This post discusses these challenges and our attempts to overcome them.
-
Moving to A(/B) Bayesian World - Part 1
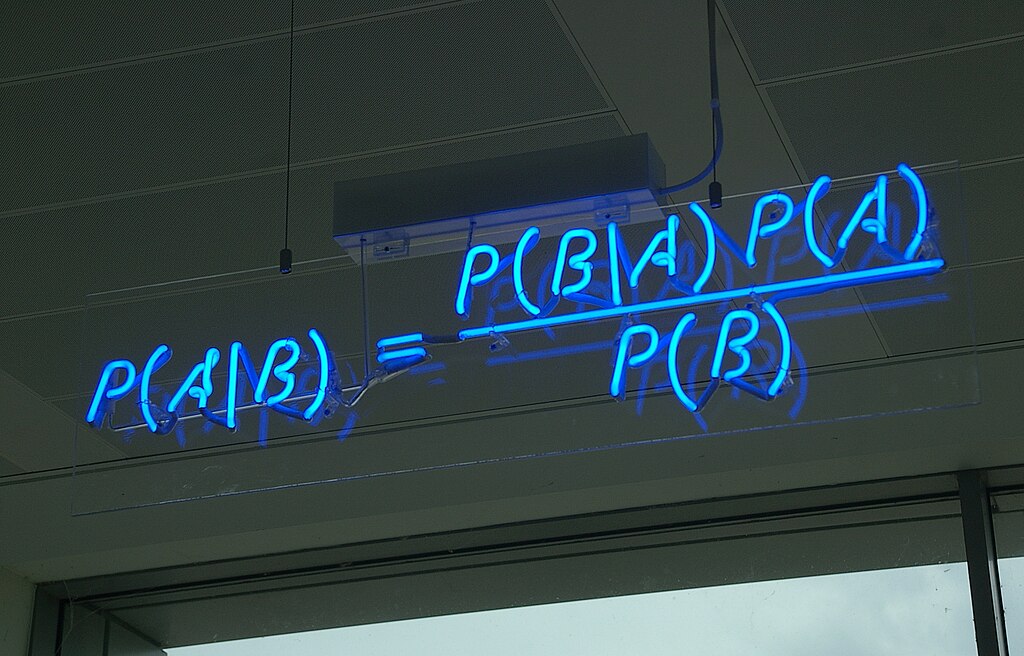
Image source: Wikimedia Commons.
Websites are constantly changing. Here at Auto Trader, we use A/B testing to monitor the impact these changes have on the user’s experience. Fundamentally, we need to gather sufficient evidence to make a decision and then communicate that to stakeholders. Ensuring that the results of any test are reported accurately and clearly is vital for a productive culture of experimentation. In this post, we discuss our move to a Bayesian framework and the advantages we believe it brings to the analysis and reporting of experiments.
-
Demystifying Large Language Models (LLM101)

Photo by Eugenio Mazzone on Unsplash.
Have you ever stumbled upon something that just completely captivated your attention? That was precisely what happened to me when I first came across Large Language Models (LLMs). It was during my preparation for interviews for my very first data science role and was learning about GPT-3. But my fascination grew exponentially when OpenAI released ChatGPT (GPT-3.5), and I am sure many fellow data scientists share this sentiment. Since then, I have been reading and learning more about them and I have also had the chance to apply them in practice and see their benefits firsthand, thanks to several projects I have worked on at Auto Trader. In this blog post, I will explain what an LLM is and how it works, and also share how we have been experimenting with Google’s LLM at Auto Trader.
-
Building a Data Academy - How we develop our data skills

Data underpins and helps to drive every part of Auto Trader’s business. With over half a million listed vehicles and 1.4 million visitors to Auto Trader per day, we have a uniquely large amount of data about the UK automotive marketplace, which is full of potential insights.
To work with that data at scale, we need enough people to know how use it in order to unlock its full value. Crucially, teams need the autonomy to help themselves to any relevant data and generate insights without having to rely on a centralised Data Engineering team. We are making good progress towards this goal. However, it is a careful balancing act between providing technical capabilities and teaching people how to use them.
-
To App or Not to App (Rapid Data App Prototyping in the ML Experimentation Cycle)

Photo by Hal Gatewood on Unsplash.
The experimentation stage of Machine Learning (ML) development for a data analyst/scientist can be a solitary experience. Often, you will be one of the few data professionals in the team or the business, and getting feedback on your work in its raw experimental form can be challenging. Additionally, you may have to explain core data concepts or present results in an undesirable format, such as a Python notebook, which can provide additional barriers to sharing your progress. In this post we’ll discuss how data app prototyping can be used to overcome some of these barriers, as well as some of the pitfalls they may present.
-
So many labels, so little time; accelerating our image labelling process

Image source: Wikimedia Commons.
There has been great advancement in recent years in the field of image classification. With pre-trained models readily available and mature libraries making the process of developing and training your own models easy, you can simply take your data and get going… unless you don’t have a lovely clean and labelled dataset to begin with. As anyone who’s manually created a labelled dataset before will know, labelling is a slow and laborious process, and if the categories aren’t clear a priori, you may end up going through your dataset multiple times.
This is what motivated us to develop an in-house tool to rapidly speed up the creation of labelled datasets.
-
DIY Server-Driven UI, part 2: Composing Composable, our new framework

This article is part 2 in our DIY Server-Driven UI intro, for part 1 please see DIY Server-Driven UI, part 1: The motivation behind changing our mobile app development.
The traditional approach to app development was proving inefficient. Building all features twice (for Android and iOS) and the store release process was creating a considerable backlog of work. The team was becoming a blocker for product and delivery.
Server-Driven UI was the clear solution, but how could we deliver this?
-
DIY Server-Driven UI, part 1: The motivation behind changing our mobile app development
For those of you who’ve seen our Devoxx talk, please find the talk links here

This is the first in a series of articles on our experience building a Server-Driven UI (SDUI) framework for our mobile apps, called Composable.
In this article, we’ll cover the situation we were in, the problems we needed to solve, what SDUI is and why it was relevant to us.
-
Improving confidence in our tracking with auto-generated Snowplow types

Photo by Kenrick Baksh on Unsplash
At Auto Trader, the behavioural events we collect about our consumers are a core part of our data platform, fueling real-time personalisation on-site and reporting our core business KPIs. Because of this, we must ensure trust and confidence in the data we track. In this post, I will describe our recent improvements to integrate strong typing through auto-generated Snowplow types into our platform tracking capabilities.
-
Charting My Experience as a Graduate Data Analyst

After 1.5 years in the Early Careers Academy at Auto Trader, I thought it would be great to share my experience so far as a graduate data analyst and what I’ve been up to here.
Back in 2022, I graduated from the University of Nottingham with a degree in Computer Science and that marked my first year in the UK being originally from Malaysia. You can imagine it was quite a huge change for me back then being still new to the country and moving to a new city in Manchester, stepping foot into the working world. Thankfully, the people at Auto Trader made it easy for me to settle into these new environments, constantly offering support whenever I needed it.
-
Creating an enriched view of the consumer

Photo by Davide Ragusa on Unsplash.
In the late nineties and early noughties, every developer was adding a hit counter to their website. It essentially counted the number of page views you had, but it was the embryonic stage of web analytics so we knew no better. Refresh your home page frantically to gain kudos with your mates at work. Hit counters are long gone, and this early unit of measurement for web analytics is now simply called an event.
-
Navigating Turbulence with our Landing Page Performance Model

Photo by Pascal Meier on Unsplash.
At Auto Trader, we define landing pages as the first page a consumer sees when they enter our website. As you’d probably expect, the Auto Trader homepage is one of our most common landing pages, as that is usually where a consumer would start when beginning their vehicle-buying journey. In this blog post, I’ll be talking about how we’ve developed our understanding of landing pages through the production of our new Landing Page Performance model, and why it is the next step towards self-serve data at Auto Trader.
-
Impressions of the 2023 Data Council conference and Austin, Texas

Photo by Tico Mendoza
Back in April, Auto Trader gave a few of us the opportunity to attend Data Council 2023 in Austin, Texas, USA. Data Council is an independently curated conference that covers many aspects of working in a modern data-focused role, from infrastructure and data engineering to analytics tools, data science, machine learning and AI.
We were really excited about this opportunity because we all used to be part of our Data Engineering team at Auto Trader. The team has since dispersed throughout our Platform Engineering tribe, so we now have people with specialist data engineering skills embedded within data product teams. We had a great time, not just at the conference but in Austin itself. Now that the dates for Data Council 2024 have been announced, we thought we’d write a Q&A-style blog post to share our experiences.
-
Faith Driven Development
We’ve all done it. There’s a little bug somewhere in an app, an unexpected null or the like, and we throw together a quick commit to fix it. Then we push it straight to master, confidence overflowing, telling ourselves that there’s no way this doesn’t solve the problem. We’ll triumphantly declare something to a colleague to the effect of “I’ve fixed that little bug by the way – was just a one-liner”.
-
Life Cycle of Our Package Uplift Model

Photo by Nik Shuliahin on Unsplash.
You’ve done the hard work in researching, developing and finally deploying your shiny new Machine Learning (ML) model, but the work is not over yet. In fact it has only just started! This is the second part of our series on our Package Uplift model, which predicts how well our customer’s stock will perform on each of our advertising packages. We will discuss how we monitor and continuously develop our machine learning models after they have been designed and deployed to reflect the current market. See part one of this series for how we created Package Uplift.
-
Demonstrating the Value of our Packages

Photo by Stephen Dawson on Unsplash.
Advertising packages are the core product at Auto Trader. Depending on the package tier our customers purchase, they get to appear in our promoted slots or get an advantage in our search rankings. As a business, we need to know how well our products are performing for our customers, as underperformance could lead to unhappy customers and them canceling their contracts with us. Knowing the impact of a package, not just overall, but on a per customer basis allows us to make sure our offerings are fair, and quickly react to any changes we observe. In order to isolate the effect of package level and to accurately predict a customer’s performance on each product, we had to create our most complex production model to date, Package Uplift. In this blog post, we’ll cover how Package Uplift works and how it builds on our ecosystem of Machine Learning models.
-
Things I learned when building an API gateway with reactive Spring
Coming from a non-reactive and more traditional Java Spring API background, I had limited experience working with Mono and Flux. To build our Spring Cloud Gateway application, I needed to bring myself up to speed on these concepts. I hope this blog post may help others who wish to learn more about how we can use reactive streams with Spring.
-
Real-Time Personalisation of Search Results with Auto Trader's Customer Data Platform

Photo by Markus Quinten de Graaf on Unsplash
Here at Auto Trader, we aim to help customers find their perfect vehicle as quickly and easily as possible. But with over 400k vehicles advertised onsite at any one time, this can prove challenging. Whilst we provide a powerful search engine to help narrow things down, customers still need to specify a set of filters to get the most out of their search, posing the question: what if they’re not sure exactly what they want? What if they’re not sure how to find what they want using our filters? How can we help those customers?
Search filters aren’t the only way a customer can express a preference - their other activity on Auto Trader can do that as well. Each time a customer views a set of search results, they express a preference by choosing which adverts to click on. This presents us with an opportunity: we can look at this activity, model a customer’s preferences from it, and subsequently improve our search results to show more vehicles that match those preferences.
-
Scoring Adverts Quickly but Fairly
At Auto Trader, we have multiple machine learning models to predict and score properties of the advertised vehicles on our platform, from valuations to desirability. With circa 8,000 new adverts listed each day, how do we generate scores for all the new adverts that have limited observations? How do we ensure that these are fair estimates of their long-term value, and aren’t going to erratically vary day to day? In this post, we’ll cover how we have addressed these problems in the case of one of our core models, Advert Attractiveness, which scores adverts based on their quality.
-
Non-disruptive in-place K8s cluster upgrades at Auto Trader

Photo by Markus Spiske on Unsplash
At Auto Trader, we keep our Kubernetes clusters up-to-date to the latest or T-1 version available in the Google Kubernetes Engine ‘stable’ release channel. We run large clusters (450+ workloads, 2k+ containers) and perform these upgrades within normal office hours without negatively impacting our Software Engineers or compromising our service availability. This post is about how we do that.

{kind=link}
{kind=link}
{kind=link}