Using syntax trees for text mining
So far, machine learning techniques such as data cleansing, frequency mapping and clustering have allowed us to peek at the topics behind a huge quantity of calls from our customers. We’ve been able to show statistics on what our customers think from unsupervised learning. But what if we could employ a deeper understanding of the meaning of the text itself in our text mining?
Luckily there are a wealth of libraries available that can parse sentences into a syntax tree, allowing us to extract the meaning of the sentences, rather than singular words. One such library is SpaCy.
SpaCy’s syntax tree
SpaCy allows us to parse any piece of text, constructing a syntax tree that allows us to extract the part of speech of each word, and the relationship between them. Let’s see the SpaCy visualizer in action.
Here we’ll use an example from our training data, the textual content of our ticketing system created when customers call us. One of our calls contains just the text:
Kerry called as customer received text. Advised there is a scam going round and not to click on any links. Emailed security
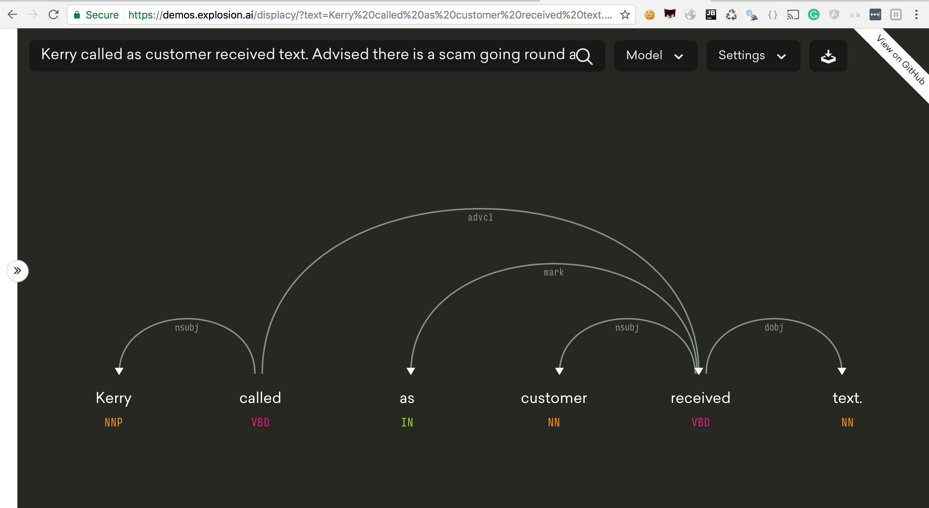
We can see that SpaCy understands the part of speech a word is, as well as its relationship to other words in the sentence. How can we use this?
N-grams with ORGs
In our previous blog, we looked at mapping the frequency of n-grams. An n-gram is a contiguous sequence of words. If SpaCy could pick out the right words, we might find out some useful information.
One very useful entity type is the ‘org’. SpaCy can retrieve organizations from text without our needing to add them to a custom dictionary.
For example:
text = 'Suggested after acc. has been canx. he can place PAYGO ADs'
tokens = parser(unicode(text))
print([token.orth_ for token in tokens if token.ent_type_ == 'ORG'])
[’PAYGO’]
This retrieves ‘PAYGO’ as an ‘org’. PAYGO is a very important offering in Auto Trader, which we would be interested in hearing about, but as an Auto Trader specific term, does not appear in any English corpus. Looking at other “orgs” in our calls, we get:
[‘Accounts’, ‘BACS’, ‘PAYGO’, ‘ATM’, ‘S2’, ‘DPS’, ‘BMW’…..]
Now, if we gave more weight to n-grams containing these terms, we would get much more useful information than the frequently used ‘Customer called’.
But can we do better than n-grams? We know that the meaning of a sentence is contained in just a few of the words, but what are the chances that those words are contiguous? One useful way of stripping a sentence back to its raw meaning is to extract SVOs, subject-verb-object triples.
Replacing N-Grams with SVOs
SpaCy itself doesn’t extract SVOs but there are several open-source libraries that can.
3 libraries to try
Textacy is a powerful library built on to of SpaCy.
from spacy.en import English
from textacy import extract
parser = English()
note = "the girl ate an apple"
parsed = parser(unicode(note))
svos = extract.subject_verb_object_triples(parsed)
print([svo for svo in svos][0:20])
[(girl, ate, apple)]
This works, but if you replace it with a lot of complex sentences, we don’t retrieve anything.
parse.py is a library built on top of Stanford Parser. It retrieves some SVO triples, but throws an exception for some longer sentences.
The library we chose was written by NSchrading, and recommended by them in their blog https://github.com/NSchrading/intro-spacy-nlp/blob/master/subject_object_extraction.py
import pandas as pd
sentences = pd.read_csv("ourdata.txt", encoding="utf-8")
def addSvos(row):
note = row['NOTE']
parse = parser(unicode(note))
svos = findSVOs(parse)
row['SVOS'] = svos
return row
with_svos = sentences.apply(addSvos, axis=1)
print(with_svos['SVOS'][11],with_svos['NOTE'][11])
([(u’customer’, u’received’, u’text’), (‘there’, ‘is’, ‘scam’), (‘scam’, ‘click’, ‘links’)], u’Kerry called as customer received text. Advised there is a scam going round and not to click on any links. Emailed security’)
Here we’ve retrieved the main meaning of the sentence in just a few words, without any need for scanning more documents.
Alterations to the SVO library.
While this works reasonably well for fully formed, grammatical sentences, a lot of our call descriptions will be sentence fragments. For example,
‘called to switch off them to personal email address.’
When we run this, we get an empty list. It seems useful to include the ‘verb-object’ pairs where a subject can’t be found.
With our alterations we get the tuples:
(‘None’, ‘switch’, ‘them’), (‘None’, ‘switch’, ‘address’)
We also found another issue when extracting SVOs.
The call description
“’transfer to Chris to talk about website and ads”
returns an empty list of SVOs. Looking at the visualizer, we can see that “website” and “ads” are classified as “pobj”, which is not included in the library’s list of objects. Adding “pobj” to the OBJECTS list in our clone of the library, we now get a list of tuples:
([(u’transfer’, u’talk’, u’website’), (u’transfer’, u’talk’, u’ads’)]
Strictly speaking, “transfer” isn’t a subject, but it is useful for meaning of the sentence.
What We Saw
Using the updated SVO extractor, we were able to retrieve SVOs for nearly all the calls.
Let’s look if any SVOs crop up more than once.
Frequency of SVOs
Looking at the SVOs sorted by frequency, there is still quite a few SVOs that don’t tell us much useful info, for example, our most frequent SVO is
(‘ticket’, ‘raised’, ‘dps’)
appearing 12 times, which basically just tells us that our support staff raised a ticket in their ticketing system.
We do get some useful info about issues with our systems. For example,
('customer', 'cancel', 'atm') appears 5 times;
('issue', 'upload', 'atm') appears 4 times;
('issues', 'placing', 'atm') appears 3 times.
This indicates that there may have been an issue with one of our popular products.
If we are to get much better results with frequent SVOs, we’ll need to do some document cleansing as described in the previous blog.
Notice that none of the verbs are stemmed. So ‘placing’ would be treated as a different word from ‘placed’ or ‘places’. The nouns could also do with some work, for example, here, “issue” and “issues” are dealt with as different words, and we could group synonyms to further increase frequencies of popular SVOs.
Filtering SVOs by Org.
Earlier we looked at clustering on ngrams which contain an org. What if we filtered our list of SVOs by some popular orgs to find out if any unusual activity is happening with our known products?
We took our 100 most popular orgs, removed some unhelpful ones, like ‘Customer’ and ‘DPS’ (our ticketing system), giving us a list of 71 orgs, many of which are our popular products.
We then filtered the list of SVO to contain an org somewhere in the SVO triple. We got 186 SVO triples with 4 as the highest frequency for that SVO triple. This is quite a small amount of data to look at, compared to the 15000 calls that we started out with. We still got quite a lot of noise, but we retrieved some issues that would have been like finding a needle in a haystack otherwise.
For example,
(‘dd’, ‘!taken’, ‘payment)
appeared twice, indicating that something may be wrong with DD. If we had this running in real time as a word cloud, or SVO cloud, we could very quickly see issues as they appeared more frequently!
Conclusion and Next Steps
So is this useful for Auto Trader?
Auto Trader has a great many products and applications, which constantly change, and tend to have nicknames or acronyms used by our support staff. Searching regularly for such a large number of applications through manual processes is just not feasible, and is likely to allow us to overlook a new or less popular product that could be becoming an issue.
Using an automatic understanding of the meaning of our vast amount of call information provided by tools like SpaCy allows us to quickly sift through the noise, and see issues as they occur.
There’s still a lot to do on this front, like creating a usable interface, productionising it’s use, and further cleansing the documents to achieve the best results, but looking at this data has allowed us to understand a lot about what can be done to understand our customers better.
Enjoyed that? Read some other posts.
