All The Small Things
Operations Engineers at Auto Trader play a critical role responding to service impacting issues and quickly restoring service. Our web applications run on Linux and Windows servers and are hosted on VMware, private and public clouds. We are responsible for monitoring these applications and responding to system generated alerts and incidents whilst performing routine trend analysis. In previous years the Operations Engineer discipline followed a daily task timetable which included lots of manual jobs. This is very inefficient and can be impacted by human error. Over the past year, the Operations Engineers have been learning about various programming languages and leveraging the benefits of third party APIs to help with reducing the amount of repetitive, tedious tasks. This has been with a goal of making our processes more efficient, which has freed up time to allow us to carry out more proactive work and increase our knowledge of new technologies.
We receive lots of questions about our on-call schedule. This is managed by PagerDuty and the details of who is on-call aren’t available to the whole business. Therefore we needed a way to increase the visibility of our on-call schedule. Slack is the most visible way to share our schedule with other teams. To improve this I used the PagerDuty API to collect the on-call data and use Slack’s API to update a relevant Slack channel via a scheduled task in our continuous delivery tool. The task provisions a pod in Kubernetes and terminates the pod when the job has finished. I’m also going to investigate running this in Amazon Lambda following a suggestion. This has received good feedback from other teams at Auto Trader and I believe PagerDuty are going to build this feature into their Slack integration.
Another piece of automation we completed was around leveraging APIs for our load balancer and DNS service (we use F5 for Local and Global Traffic Management) to create all the config for new private cloud applications. Following the addition of the script the user only needs to specify the application name and environment in our continuous delivery tool. It then creates all the associated config based on the environments. This resulted in removing a long drawn out manual task which normally took around 90 minutes and the automated tasks take around 60 seconds per application.
Another example is a script that allows the delegation of URL blocking on the firewall. I used the firewall’s API to allow our service desk and security team to block URLs without needing SSH access to the firewall. This meant the front-line teams dealing with these issues no longer needed to wait for a Network Engineer to make the change.
Where do you start?
I have been learning how to build scripts and apps which have been written in Ruby. However, these examples are applicable to any programming language. The methods you use to learn are specific to your learning style. I started off with video tutorials and guides on YouTube and LinkedIn Learning. These enabled me to work through scenarios creating small scripts in Ruby. Specifically, I found the course on LinkedIn Learning called Ruby Essential Training: 1 The Basics really beneficial with learning the basics of Ruby. LinkedIn Learning also has similar courses for most languages.
Another method of learning is to read books on the topic. I was recommended Ruby on Rails Tutorial (Rails 5) which walks you through creating a Ruby on Rails app.
Pairing with colleagues is also a good idea, even if they aren’t in your immediate team or squad. By working with someone experienced in a particular language, they can correct any small mistakes you are making and review your ideas. This is incredibly helpful as they may suggest ideas you haven’t thought about and make sure you don’t try something that is overly complex for no additional benefit.
Having a task to complete is also a great way to learn in my experience. This allows you to use a combination of the methods mentioned above to complete your task. If you have a real-world goal you will encounter specific problems you wouldn’t see if you completed a test scenario.
Changing culture
A great example of how the culture has changed in operations can be seen in our GitHub history. When I look at my GitHub contributions over the last three years there has been an immense increase.
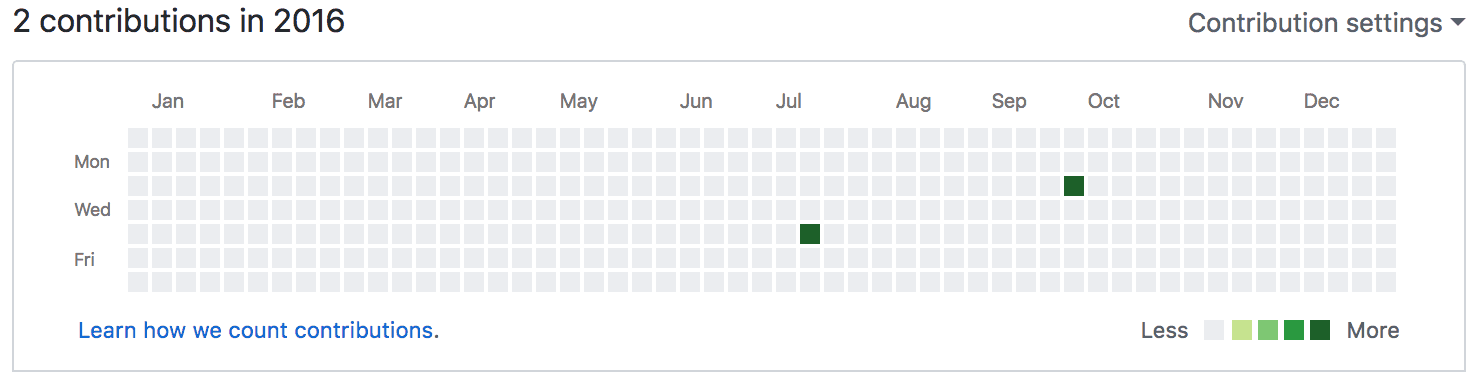
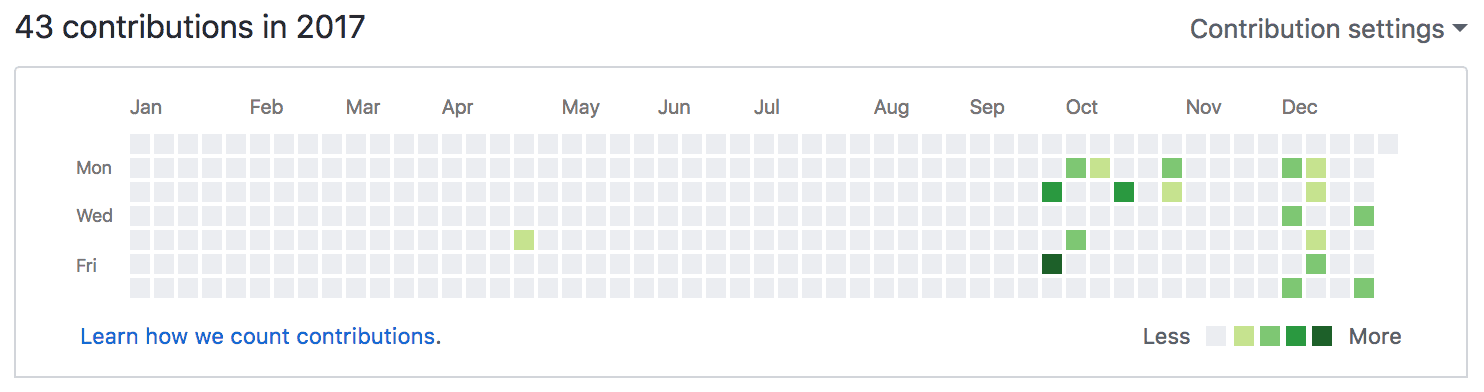
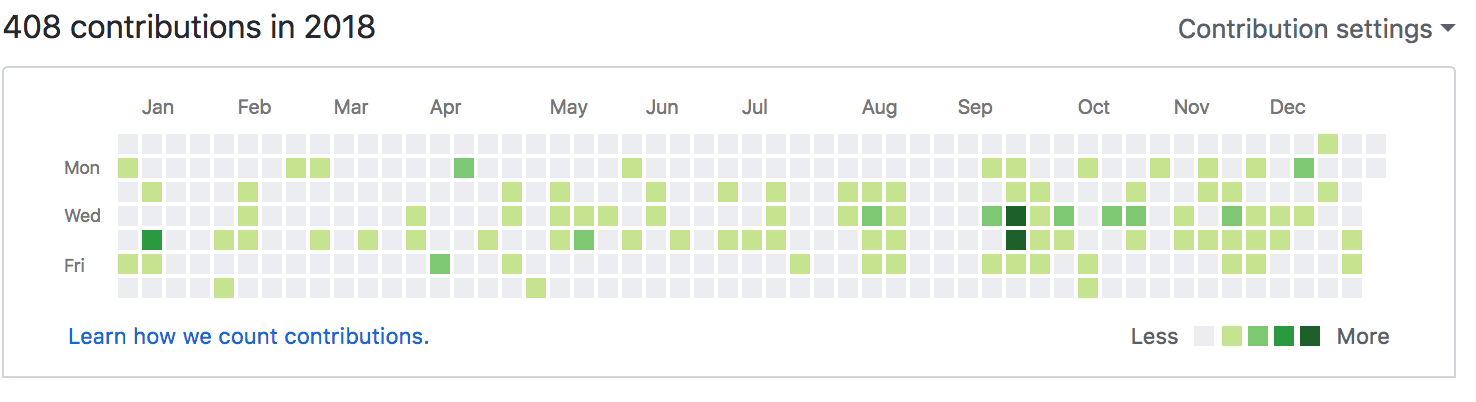
This has been achieved by following some principles created in our Operations tribe a few years ago. The principles emphasise the importance of simplicity, collaboration and repeatability. Using GitHub has greatly improved collaboration in Operations as we can work together to improve the code by making it simpler and more efficient as a team. We also used pairing and teamwork when working on automating our Load balancer and DNS configuration.
What is next?
I am continuously looking to improve our processes and since learning how to automate these tasks, I always look for a way to make a process efficient and have the least amount of manual input. I also look at the APIs for services we use and see if we can utilise the data returned or complete any of the functions we use. I am investigating all the tools used by the Operations Engineers and will review if they need re-writing for our public cloud platform. An example of this is an internal application called ‘The Blob’. The Blob queries our external monitoring provider and displays any warning or failing tests in a highly visible manner that allows us to investigate the issue quickly. We display this application on all of our wall-mounted dashboards, allowing users who do not have access to our external monitoring accounts see the status of our tests. This may need rewriting as the application is very old and uses a method our provider will not support in the long term.
Another thing we are looking to improve is the testing aspect of our automation as we currently haven’t done a great deal. I am going to be looking at this with an internal application I have been developing, which is a dynamic inventory of our external monitoring tests with useful information on previously seen issues and how to fix them. I will investigate creating smoke tests to make sure the critical functions are being completed and look at regression tests for new features and bug fixes. This will reduce the time needed for manual testing and will help to avoid introducing any bugs.
Enjoyed that? Read some other posts.
