Supporting Building a Data Lake
Data is king. Information is power. It’s not just about storing lots of it though. There is no point having years of data without the ability to interrogate it and surface the information required in a timely manner. We at Auto Trader recognised the power of data some time ago. As our data set grew there was a realisation that we needed a better structure, we needed quicker queries.
WE NEEDED A DATA LAKE!

If you don’t know what a data lake is, here’s a very brief explanation:
A data warehouse stores data in files or folders in a hierarchical manner whereas a data lake uses a flat architecture. Every bit of data in the lake has a unique ID and is tagged with sets of extended metadata tags. When you need information, the data lake can be queried for relevant data, and that smaller set of data can be accessed to get the data you need. The ability to append your own metadata enables you to make it very easy to search your data. For example, the police store thousands of files from crimes that need to be kept for years and years in some cases. They could append the crime number, location of crime and suspects to each video as part of the metadata. Searching millions of videos based on crime location to trend the amount of criminal activity in a certain town/city would be so much easier than it would be on file/block storage.
This blog will be about the thoughts and decisions made around the network/storage elements of setting up a data lake.
How Do We Design It?
As the most popular software framework for working with large amounts of unstructured data we decided to do a proof-of-concept with a Hadoop cluster.

On-premise or in the cloud?
We have always used NetApp FAS/AFF series devices for almost all our enterprise storage needs. The NetApp FAS series can be used as a SAN or NAS device. It can serve almost all file and block protocols. NFS, SMBv3, iSCSI and Fibre Channel can all be done on the FAS/AFF series.
We had two pairs of NetApp FAS3250 storage system that we had been using for storing our Oracle DB’s available because they had been replaced by more powerful NetApp All-Flash Storage systems. We decided to use these for our on-premise Hadoop POC.
When using the FAS3250’s for the Hadoop POC the performance was quite good, but we soon realised that the 40TB of storage we had available on these NetApp clusters was not going to last very long if we let all our applications insert data/logs/metrics into it.
This made us question whether on-premise storage was the right fit for starting our own data lake. We worked with several storage vendors for an on-premise solution but the main concern was that we couldn’t provide a figure to the vendors of how much storage we actually needed. This meant we either had to over-spec our on-premise solution to make sure we’d have enough space for masses of growth or take the risk of running out of storage. Being able to scale out storage very quickly without having to make a large up-front purchase was proving to be very difficult with an on-premise solution so we looked at public cloud offerings. If we used a public cloud to host our data lake service, we could scale out compute and storage almost infinitely, in an instant.
After much discussion, the decision was made to use Amazon’s Elastic Map Reduce service and S3 for the storage piece. The main driver for this was the benefits of public cloud as mentioned earlier. S3 and EC2 would enable us to grow compute and storage indefinitely. Amazon EMR is “a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data.” With EMR being a service, you can have the confidence that all the components will work together.
Network Connectivity
Once we knew where our data lake would be hosted we started looking at the AWS setup and how we might connect to our EC2 instances and S3 buckets from our offices and data-centres. We needed something that was performant but also secure. Below are the two options that were available to us.
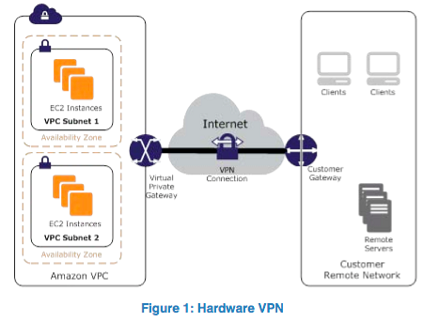
1. Lan2Lan VPN.
This provides a secure tunnel from your corporate network to your AWS VPC which essentially makes it an extension of your internal network. The traffic goes over the Internet to get to AWS but it’s encrypted. If you’re connecting to an S3 bucket, you connect via a public IP address, so to force this traffic through your VPN, you’re going to need to include almost all Amazon IP’s in the ranges you send down the tunnel. This will likely include traffic to Amazon.com so this is something to consider.
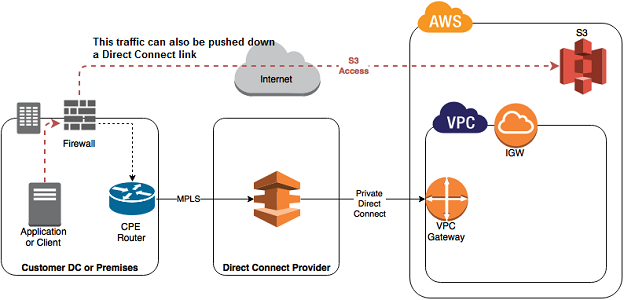
2. Direct Connect.
AWS Direct Connect is a direct link into an AWS Data-Centre. If your servers are in an AWS Direct Connect Location you can private link into the AWS cloud. Traffic leaving your data-centre will never go out onto the public Internet. Instead, traffic will stay on your Direct Connect providers network until it reaches an AWS data-centre. This means you know exactly how much bandwidth you can have and can also get a very good idea on the latency of traffic going to any services running in AWS.
Setting up the VPN
We already had multiple Lan2Lan VPN connections setup so to start we went with a L2L VPN to Amazon. This meant we could get up and running very quickly from a network connectivity point of view. The L2L VPN’s were planned to be a temporary solution while we negotiated with suppliers for a ‘Direct Connect’.
Setting up the VPN was straightforward once you get your head around how it works. Here’s some Amazon terminology you’ll need to know when you’re setting your VPN up:
-
Customer Gateway: This refers to the VPN device on your network.
-
Virtual Private Gateway (VPG): Think of this as the router for your VPC.
-
VPN Connection: This is where you enter the config for the VPN. You set the customer gateway and VPG and the VPN connection is initiated. You also need to specify whether you’re going to use static routes or BGP.
How do we maintain it?
As there is no physical kit for us to manage in AWS, it made sense to deploy and make changes to our VPC infrastructure as code. Terraform was recommended to us by a company we consulted about moving workloads into AWS. Terraform is a tool for building, changing, and versioning infrastructure. Terraform configuration files define your infrastructure. You edit these and then Terraform manages the API calls that need to be made to your cloud provider to push these changes to your environment. Terraform also seemed to be widely used when doing infrastructure as code in AWS. We’d had some experience of automated network config change with SolarWinds NPM, but that just pushed out the IOS code which we all understood as Network Engineers.
Here’s an example of setting a network as a variable and then referencing that variable in a routing table for a VPN connection in Terraform:
-
Set the network as a variable
variable "at_subnet_server_network" { default = "172.0.0.0/8" } -
Set that variable as a route on the VPN
resource "aws_vpn_connection_route" "emr-dc2-cloudstack-dc1" { destination_cidr_block = "${var.at_subnet_server_network}" vpn_connection_id = "${aws_vpn_connection.emr-dc2.id}" } -
Set the route on the AWS VPC to send traffic for that network down the VPN
route { cidr_block = "${var.at_subnet_server_network}" gateway_id = "${aws_vpn_gateway.emr.id}" }
Conclusion
Not all services benefit from being moved into a public cloud like AWS. From an infrastructure point of view though, a data lake is an ideal candidate. The ability to scale up and down on demand with cost being the only limiter for growth is a real bonus as it’s something we couldn’t do on-premise without a very large up-front cost.
Automating network changes and using version control is something we’re already starting to implement on our in-house networks after seeing the benefits of this while using Terraform and AWS. Managing our core infrastructure as code is something we are likely to implement in the future.
Enjoyed that? Read some other posts.
Related Posts
19 Jun 2024—Stevie Woods and Philippa Main

Data underpins and helps to drive every part of Auto Trader’s business. With over half a million listed vehicles and 1.4 million visitors to Auto...
05 Apr 2024—Bethanie Garfin
Photo by Kenrick Baksh on Unsplash
At Auto Trader, the behavioural events we collect about our consumers are a core part of our data platform, fueling real-time personalisation on-site and reporting our core business KPIs. Because...
