Non-disruptive in-place K8s cluster upgrades at Auto Trader

Photo by Markus Spiske on Unsplash
At Auto Trader, we keep our Kubernetes clusters up-to-date to the latest or T-1 version available in the Google Kubernetes Engine ‘stable’ release channel. We run large clusters (450+ workloads, 2k+ containers) and perform these upgrades within normal office hours without negatively impacting our Software Engineers or compromising our service availability. This post is about how we do that.
Platform Abstractions
Right at the beginning of our Kubernetes (K8s) journey, we decided to go with Google Kubernetes Engine (GKE) as a managed K8s service on the Google Cloud Platform (GCP) to abstract away underlying maintenance concerns. This allows us to have a small team of Platform Engineers who still can make improvements, updates, and changes to our platform. Consequently, we retain lots of control over how we use Kubernetes at Auto Trader, but without the huge engineering overhead of deploying our own clusters.
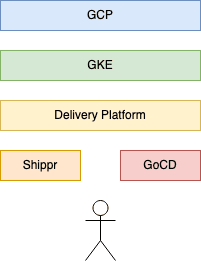
We then abstract the configuration and management of the cloud infrastructure away. We believe that platform concerns are not the best use of our Software Engineers’ time and instead, we enable them to focus on their software. We do however believe in Infrastructure as Code (IaC) and making hardware configuration available to project owners and maintainers. The thing which bridges the gap between K8s, the code which exists in application repositories, and the Continuous Integration / Continuous Delivery CI/CD system which deploys everything is an in-house app named Shippr. Shippr acts as an interface for Software Engineers to release and deploy applications.
The result is a transparent Platform as a Service (PaaS) we call the Delivery Platform. Although it now makes our lives immeasurably easier at Auto Trader, its creation presented some interesting challenges along the way.
Challenges
We decided to perform K8s in-place upgrades from the outset. The alternative would be to spin up completely new clusters on a new K8s version and then migrate workloads over to them. There would also be a requirement for appropriate testing of the new cluster, and this would take time and more engineering effort to manage and create. In-place upgrades offer huge time-saving benefits but could add challenges such as potential impacts to Software Engineers; if we’re going to provide a PaaS, the impact upon releasing software must be kept to a minimum.
In-place upgrades offer another challenge - rollbacks of the Master nodes are not possible - even in GKE. This means we need a robust testing mechanism to give us the confidence to upgrade our clusters through to our Production environment (prod) without irreversibly breaking something.
Some of our apps also have some special requirements in their lifecycle where container preStop hooks are just not enough. Some of these apps (more about these later) rely on Apache Solr which in turn relies on state.
Additionally, the K8s suite of Application Programming Interfaces (APIs) are regularly updated, meaning we need a way to detect and alert on changes that require action, be that to move to a new version or a different supported API.
Developer Contract
To overcome these challenges we came up with what we call the Developer Contract. As with any ‘as-a-service’, there is a necessary agreement between both parties describing what is expected from one another. In a nutshell, this is to provide robust platform features in exchange for robust application design - this feeds into our upgrade strategy as well.
On the Delivery Platform, we enforce a series of best practices to ensure the Developer Contract is fulfilled. We do that by running a series of build and deploy validation checks which can report any violations both by running it locally on a laptop through our in-house Command Line Interface (CLI) named shippr-cli, and automatically at build time via our CI/CD application, GoCD. The validators are run by the Shippr app when each application is built. The validators and how we do this are a little out of scope for this post. If you want to hear more on those, please let us know in the comments.
Also included in the Developer Contract are some application requirements:
Applications should:
Be designed and built to fail gracefully at any time
Gone are the days when we would develop long-running robust application pets. We’ve worked hard to move to cattle applications that are designed to fulfil one purpose, be short-lived, and handle failure gracefully. A SIGTERM signal is issued by K8s when they’re draining the nodes, and therefore a graceful shutdown in response to being issued one is key. Unannounced cluster operations can also occur at any time, not just during our triggered upgrades. Cluster events occur when Google upgrades any underlying infrastructure, run patches, or scales hardware due to GCP utilisation. All this feeds into how important graceful application lifecycle management is in the public cloud.
Apps must present reliable health check-endpoint(s)
This is to resolve application lifecycle status through liveness and/or readiness probes. Liveness probes declare to K8s that the application is alive and running. A readiness probe declares if the application is ready (or not) to accept new connections. The combination of these two probes allows K8s to know at what stage of the lifecycle an application is at, and handle its workload appropriately. This is essential to maintain application High Availability (HA) when rolling out updates to K8s.
Run as a single PID
To keep things simple, we insist that apps run as one single process. This is to simplify our monitoring solutions, reduce the threat of noisy-neighbour apps, and speed up graceful shutdowns. When draining nodes as part of a K8s upgrade, nodes are given a termination grace period of one hour. Once this grace period is met, the node and anything remaining on it is terminated. Workloads that consist of complex arrays of processes risk getting stuck or need lengthy shutdown procedures. To prevent unclean shutdowns of workloads, a single PID is recommended.
Have a multiple of three replicas in the production environment
We run zonal clusters deployed over three availability zones for redundancy and HA. We apply locality-aware routing too. Applying locally-aware routing comes with benefits; inter-zonal egress can end up expensive, and locality-aware routing is more performant; it is faster for app A to talk to app B if it’s in the same zone, rather than connections leaving the zone to speak to the next app in the chain in another zone. We’re only talking about fractions of seconds with zonal clusters in GCP, but when we multiply that with each hop, we could end up adding seconds of latency to Auto Trader services with larger stacks. This is just one example of things to think about when working with microservices.
In production, we use taints and affinity rules to ensure that scheduled Kubernetes pods are spread over our three different zones. We provide the ability for Software Engineers to specify how many replicas they wish to have for their apps, but for production, units of three prevent request imbalances that could impact other applications in a given stack.
In return for these requirements…
The Delivery Platform should:
Allow software engineers to configure their resources via IaC
As mentioned earlier, we strongly believe in IaC as close to each application as possible. Dockerfiles and helmfiles are contained within the application repo it belongs to, allowing maintainers and owners to configure their resources as they wish. This is the same place we provide the ability to specify the application liveness and readiness probes to enable HA and upgrades. Shippr as part of the Delivery Platform takes these files (essentially using them as partials) and builds the apps and constructs the helm charts with which the application is deployed. It’s all in GitHub in their application’s repo!
Be highly available
Applications deployed in the Delivery Platform are zonally distributed using affinity rules. This is done transparently to our Software Engineers apart from production where the replicas are encouraged to be in multiples of three. We also apply node affinity rules to ensure an application’s pods are not all scheduled on the same node. If we lose a node, the application can continue to do its thing, until a replacement is scheduled by K8s.
Provide required standard resources
One of the things which we tend to get asked about when we do talks on our Delivery Platform at Auto Trader (watch this space) is how we automatically provision HTTPS certificates, Domain Name System (DNS) for applications, routing, and tested base images. We’ve worked hard to get this stuff which is hard work in the old world of full-fat virtual machines, physical firewalls, and old-school DNS servers into repeatable deterministic pipelines with appropriate testing.
There’s a whole blog article to write about the platform capabilities such as platform-provided logs, metrics & tracing of HTTP requests, and alerting / incident management based on the observability capabilities, but it’s somewhat out of scope for this article. If you want to hear more on how we do this stuff, please let us know in the comments. However [ blatant plug ]: It feels like a good time to reiterate that the Delivery Platform is shaped and maintained by a small six-strong infrastructure team who are constantly exploring new and existing Open-Source Software (OSS) components to evolve and improve the platform further. Where OSS can’t complete a task alone, we write in-house solutions, such as Shippr. It’s an exciting team where we’re allowed the freedom to evolve our technology stack in the ways we feel benefit the business the most and (we’re hiring!).
Provide a PaaS
We provide the resources above automatically as part of the Shippr release process to automatically give apps it all without Software Engineers needing to do anything. Each app gets its own K8s resource which essentially serves as a Level four software load balancer, distributing load to all available replicas of an application. When we do upgrades, all this stuff remains in the appropriate namespaces when being rescheduled, so when the pods come up on the new nodes, they can start serving immediately, being load-balanced by the Kubernetes services they live under and maintaining HA throughout.
Upgrade Prerequisites
Upgrading a K8s cluster Master is effectively upgrading the APIs on which we heavily rely all at once, and again because downgrading a Master is not possible, we have to be super careful. First up, we read the release notes to ensure we’re not introducing any surprises. Fortunately, one of the benefits of keeping up-to-date, coupled with the respectable deprecation policies of K8s, these surprises remain rare and narrowly scoped. Upgrading critical bits of infrastructure to two or three major versions is not something any of us will miss any time soon.
We stay up to date by validating the Kubernetes APIs we use in Shippr. We update a list of Kubernetes APIs and versions of those APIs inside Shippr. Any deprecated APIs in use are flagged up as applications are built. Platform Engineers then resolve them by switching to a supported version or removing or replacing them. This means that when Google publishes the next GKE version release, there are no unexpected software rewrites required to unblock us from upgrading.
Performing K8s Upgrades
We have developed some tooling that automates the upgrades via our CI/CD system, GoCD. GoCD allows us to create a rigid promotion-style deployment pipeline giving us the control and power to observe the results of an upgrade following a wait period before we manually proceed to the next environment.
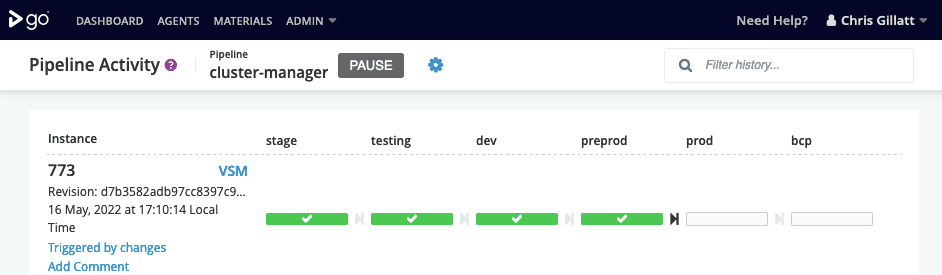
Wait periods:
- testing - once all tests pass
- dev (Development) - 1 day
- preprod (Pre-production) - 1 week
- prod (Production)- 1 week
- bcp (Business Continuity Planning)
We have four “production” Delivery Platform environments (dev, preprod, prod, and bcp) and one test environment named testing. You may be asking yourself how dev and preprod could be described as production, and this is another area where the Developer Contractor comes in. Each of these environments is expected to be available at all times; they should not need to be concerned with infrastructure testing. Each of these environments is deployed in the same way, using the same Infrastructure scripts and their availability is taken just as seriously. In software terms, only “prod” is production, but as infrastructure, all of them are.
Infrastructure Scripts
K8s can operate with node pools that are up to a maximum of two minor versions behind the Master, but the Master cannot be behind the version of the node pools. Therefore the upgrade starts with the Master nodes, known collectively as The Control Plane when there are multiple. It’s worth knowing that some people and documentation refer to Masters or Control Plane interchangeably.
On Master upgrade, the script:
- Sends an upgrade start notification to Slack
- Performs a full cluster backup containing all K8s resources
- Silences any alerts which would fire due to the upgrade (any apps that rely on the Master being available)
- Runs the Master upgrade
- Sends an upgrade finished notification to Slack
Again because we only have one Master, when it’s being updated it does mean that deployments are paused. For us, this just means that releases wait an extra 5-10 minutes while the new Master comes up and takes over. Because we run this process in our true non-production environment first (the testing environment), we’ve already tested that the upgrade should be successful and observed anything interesting. Although our “testing” environment is non-production (non-prod), it’s still deployed and maintained in the same ways as all of the other environments; we just don’t include it in the Developer Contract.
On Standard Node Upgrades for each node pool, the script:
- Sends a start notification to Slack
- Silences any alerts which might fire due to the upgrades over the next 10 minutes
- Runs the node pool upgrades in standard node pools based on maxSurge 1
- Sends an upgrade finished notification to Slack

For node upgrades, we use the rolling update strategy with maxSurge set to 1. A new temporary extra node comes up on the new K8s version in the node pool and becomes registered with the Master. For example, if the node-pool which is currently upgrading has a max number of nodes of 10, this new node would be node 11. Node upgrades are done one at a time. By the time the upgrade is complete, the node count will have returned to 10. This is to ensure that there are enough resources for your workloads throughout the upgrade process without needing to overprovision nodes to accommodate. A target node is then selected, cordoned, and the workloads rescheduled elsewhere in the node pool where there are available resources.
Touching on the Developer Contract again, each pod’s workload must be deployed with appropriate liveness or readiness probes so that they can be repeatedly scheduled elsewhere and maintain service efficiently.
To reschedule the workloads, a SIGTERM signal is sent to the container so that it can respond by rejecting new connections. This results in the container being removed from its related K8s service which acts as a load-balancer. A terminationGracePeriodSeconds set at 30 kicks in to allow the process to finish what it’s doing, after which it will be killed. Meanwhile, the pod is being rescheduled on the new node. We use maxUnavailable of 25% to ensure application HA. Disruption budgets are the overarching method of preventing disruption to services when workloads become unavailable.
Once the container’s probes are responding healthily it’s added into the service and it can begin taking traffic. Once the old node has shed all of its workloads (or hit the terminationGracePeriod for them all) it is then removed. The process begins on the next node running on the old K8s version.
Special Node Pool Upgrades
Some of our workloads need extra care when starting them up or shutting them down. Unfortunately in a couple of our special use-cases, the likes of preStop hooks alone don’t quite work for us. One of these special cases is our implementation of Apache Solr. Solr is a Lucene-based NoSQL search engine that relies on an in-memory state. It can shut down gracefully if allowed time to stop indexing and commit its state to a disk (or in our case a Persistent Volume Claim PVC so that it can be re-attached to a new workload). Therefore, we’ve modified our node upgrade process to accommodate this process.
We give these special workloads their own node pool to isolate and upgrade them separately from the others, then use taints and anti-affinity rules to ensure that only the correct workloads can be scheduled on those nodes.
The process then looks like so:
- Sends a start notification to Slack
- Silences any alerts which might fire due to the upgrades over the next 10 minutes
- Pause apps that index data into Solr
- Instructs Solr to commit its indexes
- Upgrades the Solr node pool
- Un-pause the apps
- Sends an upgrade finished notification to Slack
Post Upgrade
Once the testing cluster is completely updated, we can run additional tests to ensure our tooling supports the new K8s version. We check our infrastructure Grafana dashboards for anomalies and ensure all nodes and pods are running healthily. Then we wait the specified wait period and proceed when we’re confident everything is in order.
Wrap up
We perform non-disruptive in-place K8s upgrades in this way because we believe it to be the best strategy for our use case at Auto Trader. Our node-pools are protected using surge nodes, and the apps on those nodes protected by disruption budgets, termination grace periods and affinity rules. We use liveness probes & readiness probes for app lifecycle concerns, and we use separate node pools for special cases like GoCD and Solr.
If you’re reading this and you’ve solved similar challenges in different ways or have some thoughts or suggestions, we’d love to hear from you in the comments.
Enjoyed that? Read some other posts.
