How we used Databricks notebooks, MLeap and Kubernetes to productionize Spark ML faster
Machine learning (ML) models are nothing new to us. We’ve used them to power products such as our used car valuations and Price Indicators. The processes involved in training and serving these models are complex, involving code written by both data scientists and developers in a variety of languages including Python, Java and R. Serving predictions from these models in real time typically involves a custom application to extract the coefficients from the saved model, and apply them to an input request.
While this approach has worked successfully, we’ve come to realise that taking a model from prototype to production in this way is a slow, complex process. Even simple changes to a model require careful coordination between data scientists and developers, and carefully synchronised releases at both ends of the training and deployment process.
As we developed a new set of ML-powered metrics, we decided to see if there was an easier and quicker way to bring new models into production.
This post describes the tools and technologies we used to develop our new Days to Sell ML-powered metric and bring it into production. Days to Sell is a predictor for how many days, on average, we would expect a given vehicle to sell, considering its make/model/fuel type etc., age, how well priced it is, and where the seller is located in the country. This is powerful - it helps our retailers focus on their overall profit, considering their stock turnover instead of just focusing on obtaining the maximum profit per vehicle.
If you’re more of a conference talk kind of person, there is an embedded video at the bottom of the post.
The new approach - Apache Spark
Over the last two years, we’ve been building out our Data Platform, centred around an S3-backed data lake - a repository containing data captured from databases and streaming platforms across the business. To interrogate data in the lake we use Apache Spark. Spark provides a number of ways to interact with data, including a SQL interface for ETL-like operations, and a machine learning framework called MLlib. Since we’re already using Spark for data analysis and ETL workloads, using MLlib for our machine learning needs felt like a natural choice.
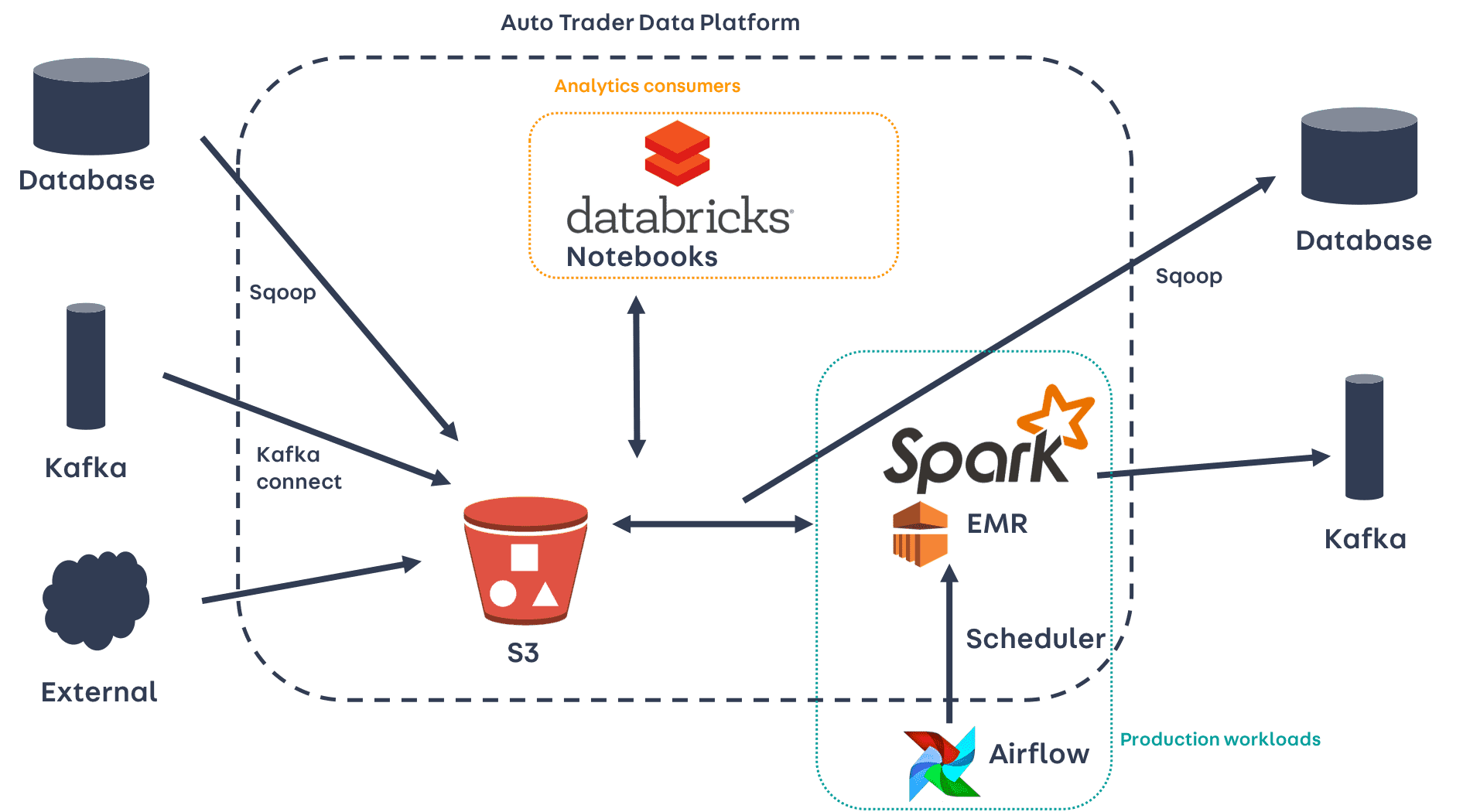
Model phases
Before jumping straight into the detail of our model, it’s worth articulating the stages involved in bringing a model into production, and why different tools are needed at different stages.
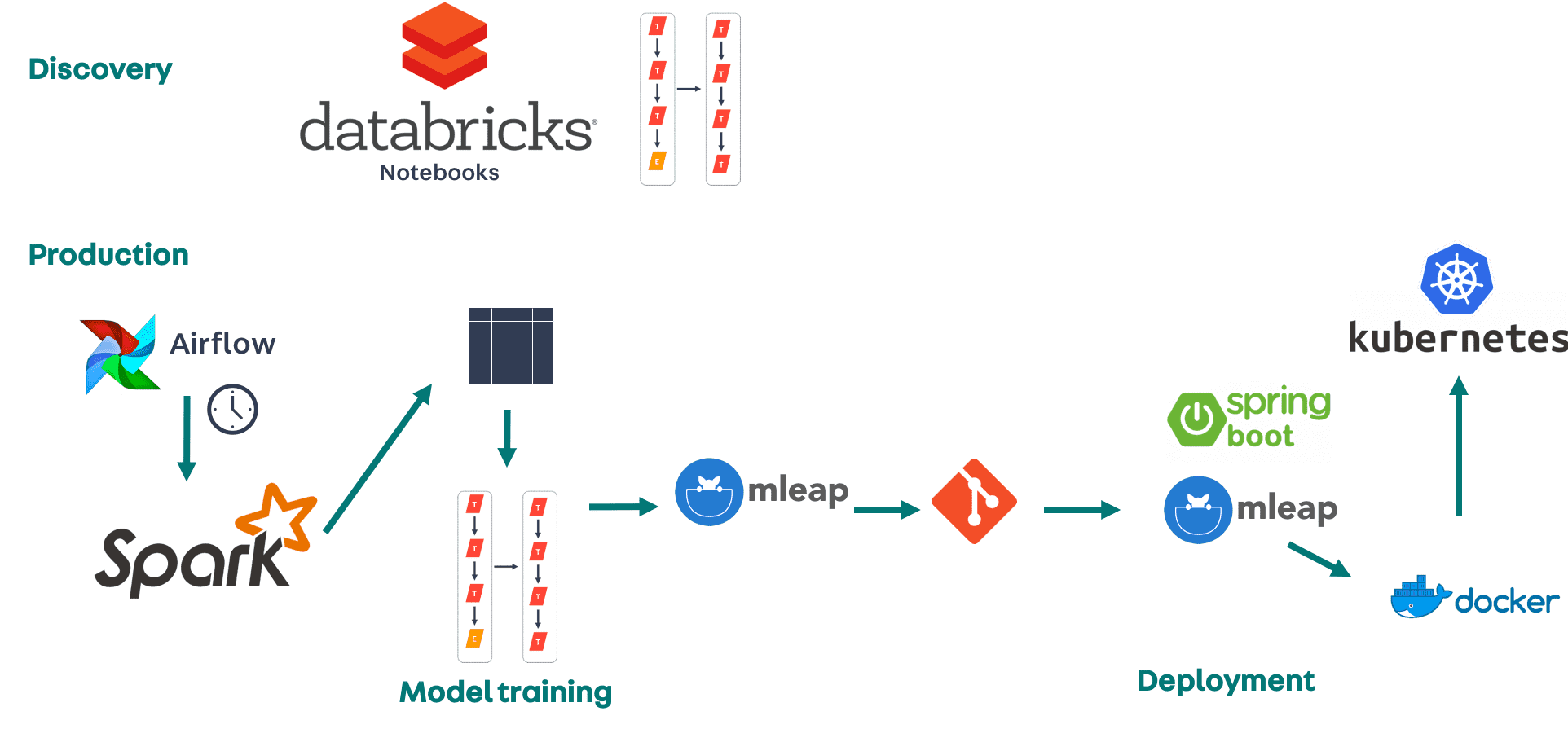
In our experience, an ML model typically has a two-phase lifecycle - a discovery phase, during which the model is developed from an idea to a prototype, and a production phase, where the model is automatically retrained and redeployed.
The discovery phase is where our data scientists experiment with ideas, bringing together different datasets and features, and evaluating the performance of different estimators. For them to be able to run these experiments effectively, they need to interact with the data in a way that allows them to iterate quickly, getting fast feedback on the impact of a change.
By contrast, in production, we require our model to serve out predictions in real time. In this phase, the model should be retrained and redeployed regularly with no manual intervention. Automated testing, including unit tests and data integrity checks, should be used to ensure resiliency and reliability. The constraints imposed by this extra resiliency mean that the feedback cycle for evaluating changes is much slower than in the discovery phase.
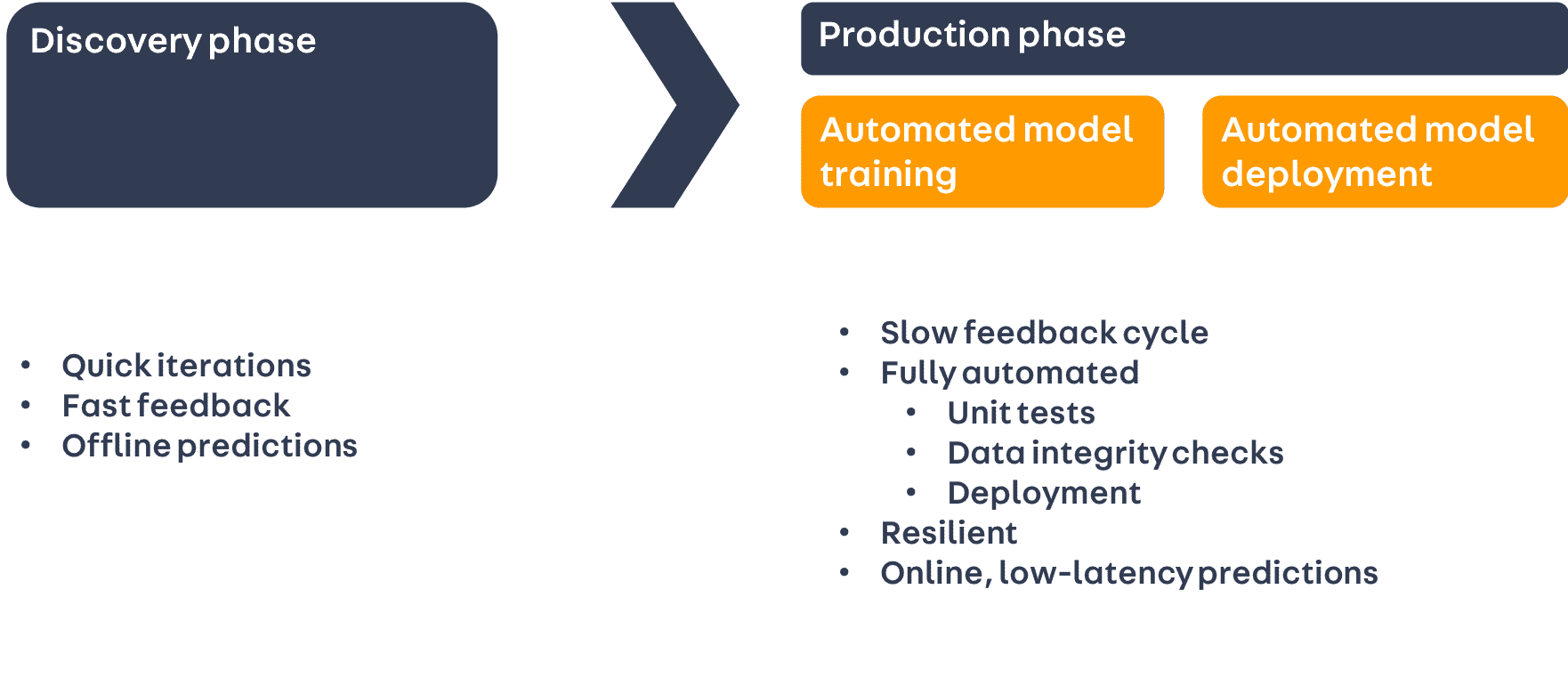
Discovery
The Days to Sell metric is powered by a mathematical model, trained on real data. Our data scientists ran experiments to determine exactly which datasets to bring together in the training data, which features to extract, and how to combine them together with estimators to produce the best possible model. A notebook tool is perfect for this sort of experimentation, allowing us to write and execute code in an iterative manner and display results using inline visualisations. In the past, we’ve used Jupyter notebooks, which we found worked well with local data, but had issues integrating with Spark, particularly with large numbers of concurrent users. More recently, including for the development of the Days to sell model, we’ve been using Databricks, which we’ve found to integrate seamlessly with Spark and provides a great collaborative environment.
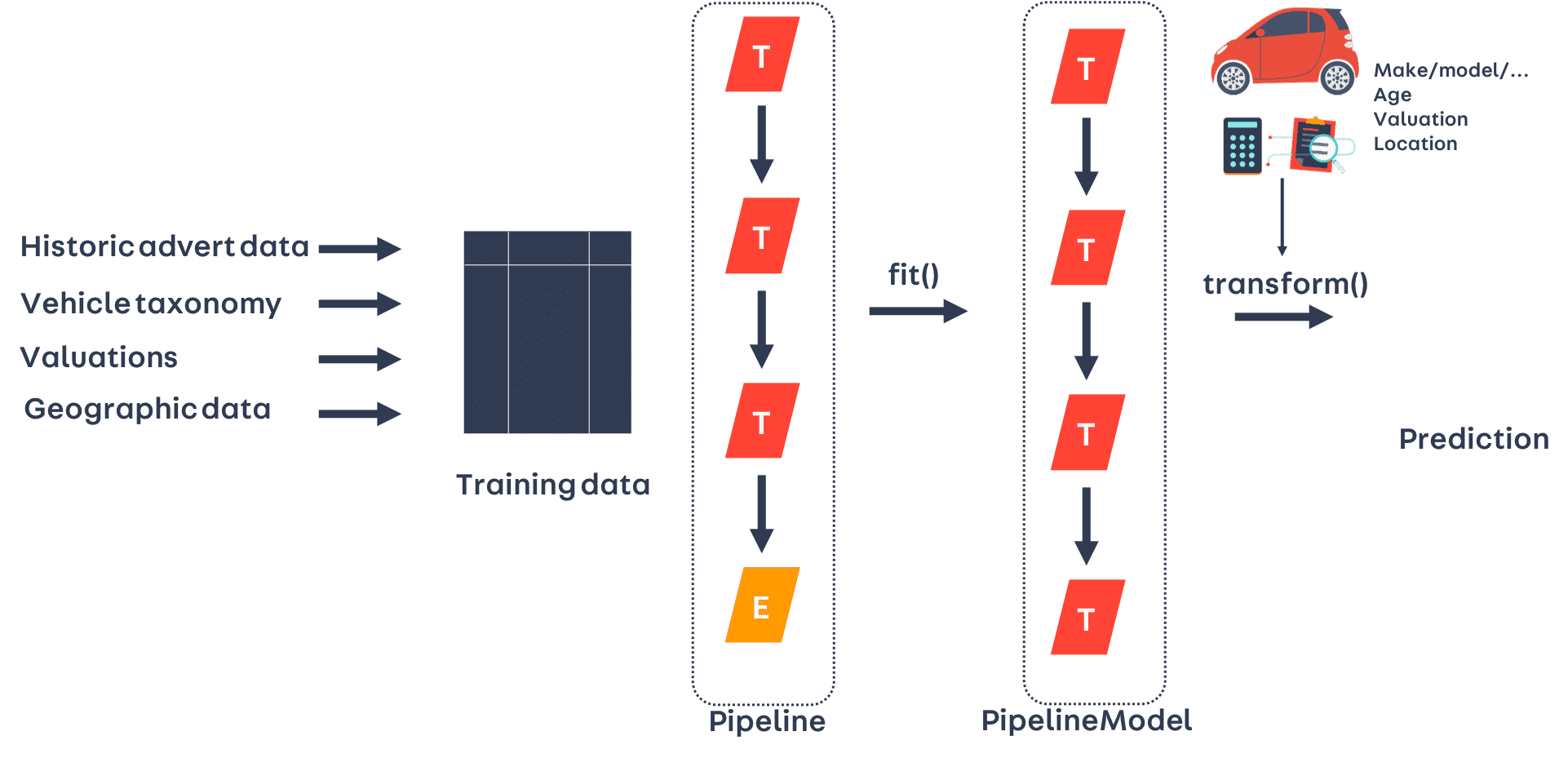
The training data brings together data from a number of sources including:
- Historic advert data
- Vehicle taxonomy data
- Historic valuation data
- Geographic data
Using notebooks, our data scientists defined a Spark ML Pipeline to extract the features of interest from the training data, and pass them into an appropriate estimator.
Once the ML Pipeline has been defined, it can be trained by calling a fit() method with the training data. This returns a fitted PipelineModel, which in turn can be called with a transform() method to produce predictions.
Finally, once trained, MLlib provides tools to serialise the fitted PipelineModel to S3 for later use.
Production
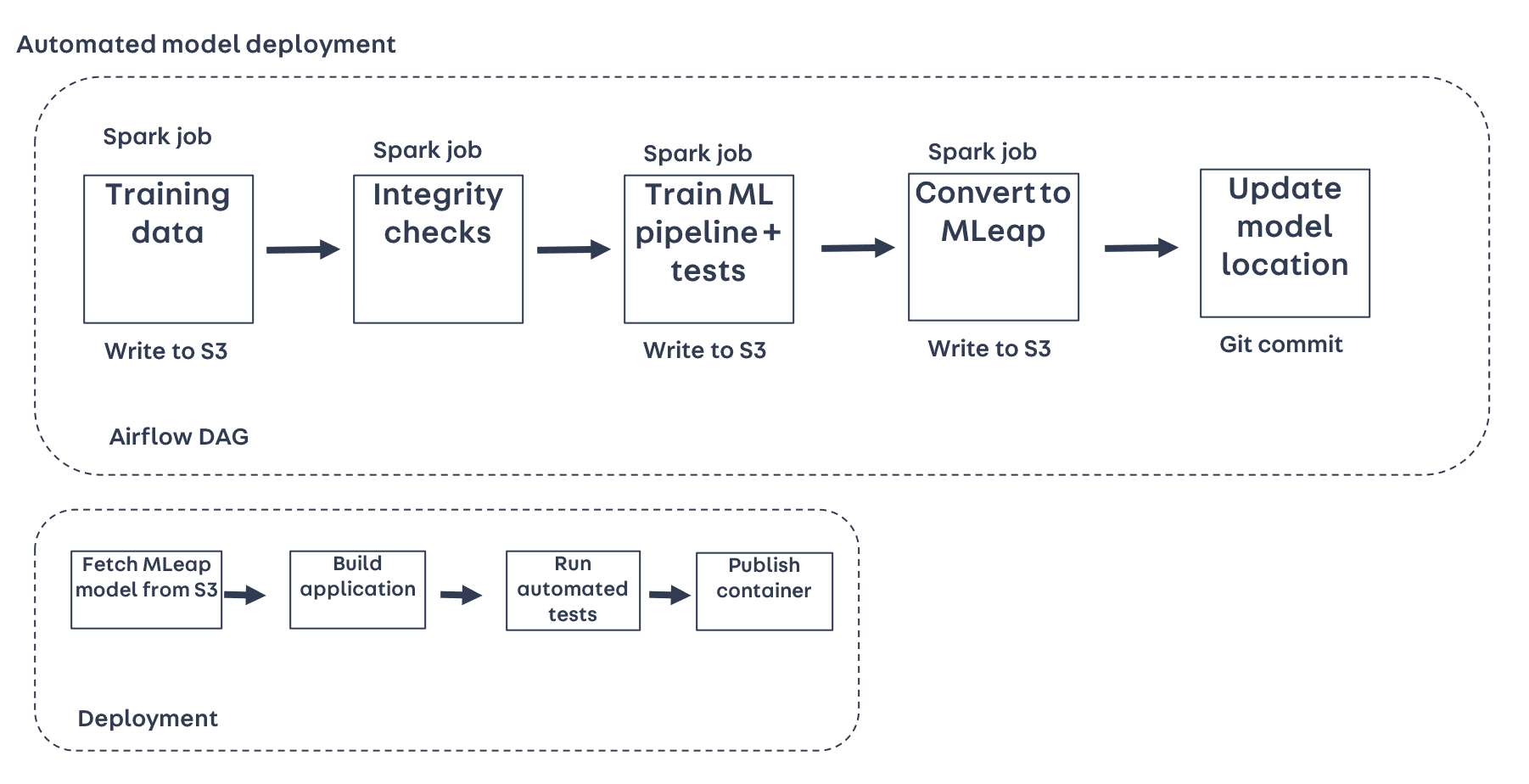
Automated model training
While notebooks provide a great environment for running experiments, they’re not ideal for running in production. Even though Databricks notebooks can be scheduled to run automatically, we opted to re-write the notebooks for producing the training data and training the model as standalone Spark jobs, to be triggered using Apache Airflow, our scheduler.
Porting the model in this way gave a number of advantages:
- It’s possible to run automated testing as part of the build process including unit tests, integration tests, and data integrity checks when retraining the model
- Building and testing is no different to any other app and integrates nicely with our existing release automation tooling
- Integration with Airflow allows us to use our existing monitoring and alerting approach
- An extra stage of code review when passing the model between data scientists and data engineers helps to share understanding about the model among our team
By comparing the training data along with the predictions from the fitted model, we verified that the ported Spark jobs were equivalent to the original notebooks.
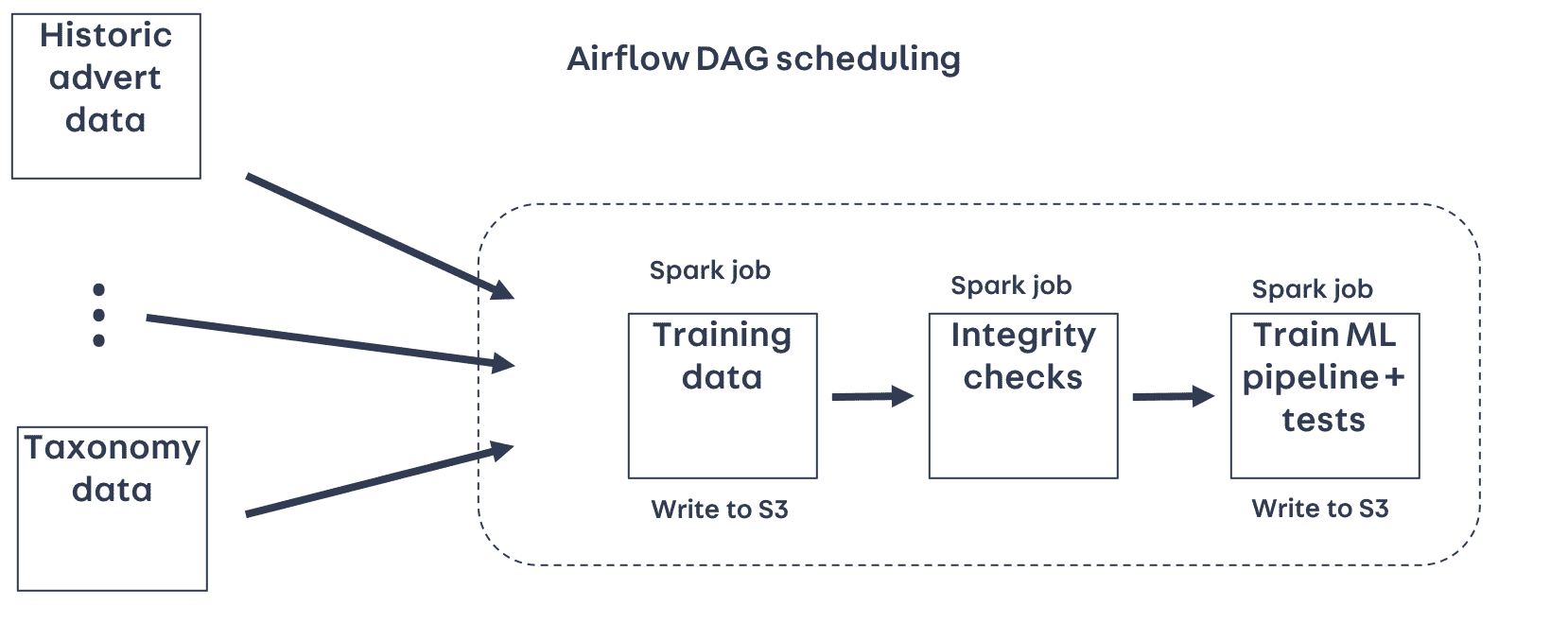
DAG scheduling
Airflow DAGs (Directed Acyclic Graphs) let us specify the relationships and dependencies between tasks, so for example, we can ensure the task to generate the training data won’t be submitted until the data it depends on (e.g. historic advert data and taxonomy data) are both in place.
Using Airflow, we defined a DAG to run the tasks involved in training the model:
- Generating the training data
- Running integrity checks on the training data
- Training the ML Pipeline, running tests on the trained model, and serialising the fitted PipelineModel to S3
Automated model deployment
We now needed to find a way to serve out model predictions in real time, while also being able to automatically redeploy the model once it has been retrained.
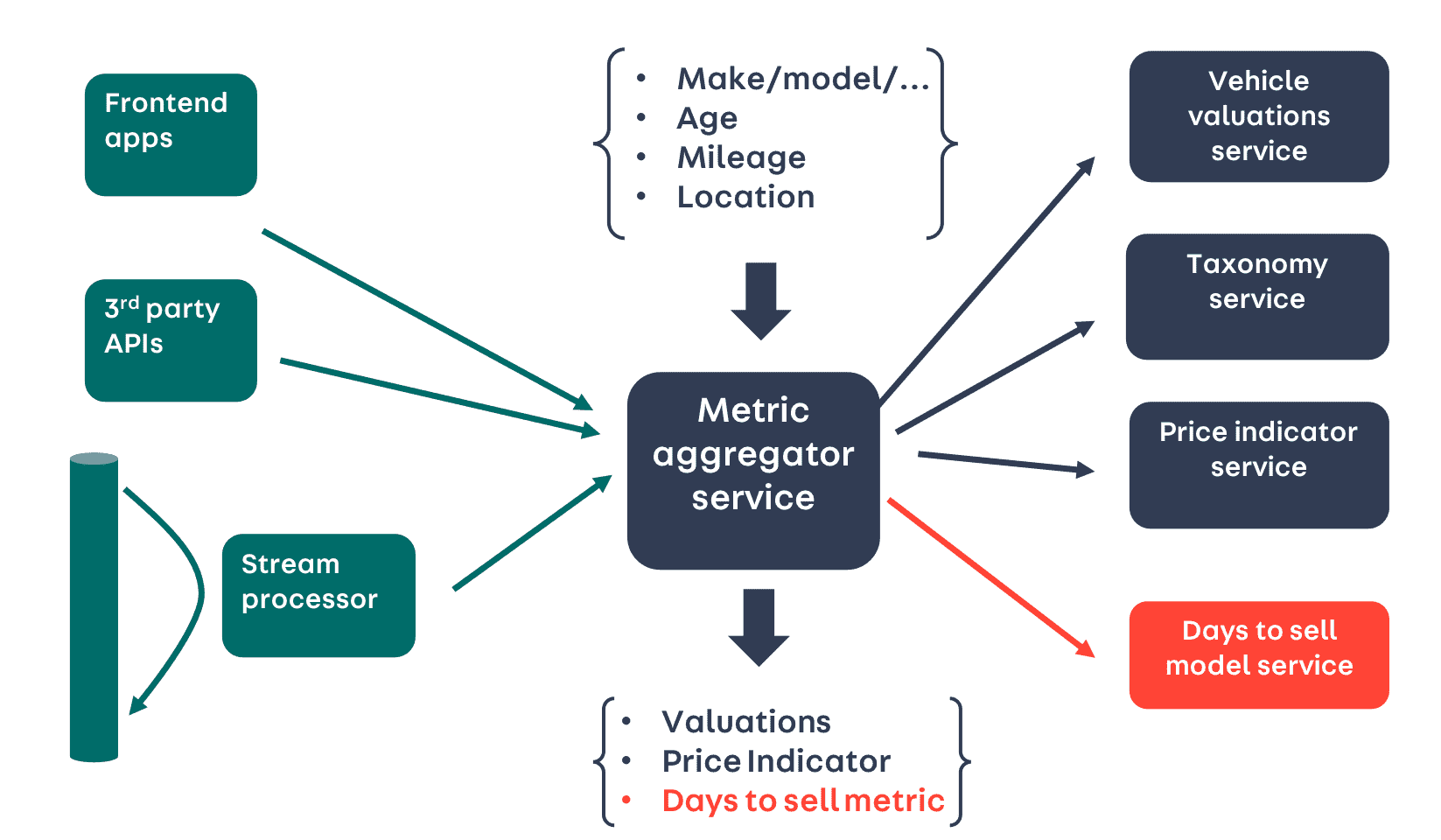
Our architecture uses an aggregating web service to serve out our existing ML-powered metrics, including valuations and Price Indicators. This web service fronts a series of specialised microservices, and is connected to by frontend apps (e.g. our forecourt management tools), third-party APIs, including auction companies, and a Kafka producer that is used to integrate these metrics into our search index. In total, this aggregating service serves over 1,000,000 requests per day. Serving out the new Days to Sell metric under this architectural pattern made sense - we just needed a new microservice to serve Days to Sell predictions.
The high request volumes along with the nature of the consumers meant that this new microservice had to serve predictions in a way that was both low latency and high-throughput.
Attempt 1 - a local Spark context
Spark is primarily designed to be a cluster computing framework, but it can also run in local mode, with the driver, executor and master running in a single JVM. Using local mode, we were able to construct a simple Spring Boot microservice, with an integrated Spark context. Using the local Spark context, we loaded the serialised ML PipelineModel and called the transform() method to produce predictions in real time as requests came in.
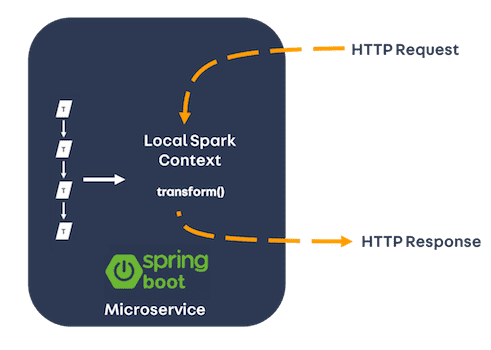
While this approach technically worked, the performance was poor. We saw typical response times in excess of 500ms, and the service was unable to handle the necessary level of concurrency.
Attempt 2 - MLeap
An alternative to running a full Spark context is to use MLeap. The MLeap framework provides a runtime that is specifically designed to serve model predictions in a low-latency performant manner.
To use MLeap, we first had to convert our serialised MLlib PipelineModel to MLeap’s own custom format. We did that in a final stage Spark job in our model training DAG.
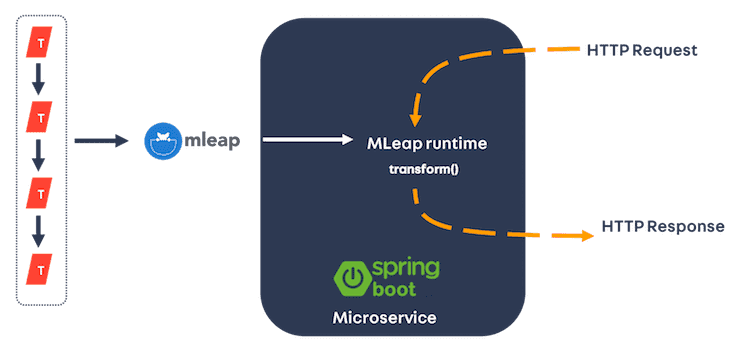
The MLeap runtime is initialised inside the microservice and is used to load the converted MLeap model. Once loaded, a transform() method is provided that works just like the original PipelineModel to produce predictions.
Using MLeap the response time was vastly reduced - 90% of responses were served in under 30ms, and a pool of two services is ample to handle our throughput requirement.
Containerising the service
Now we have an MLeap-converted model, and a service to serve out predictions. We need a way to package them together as a deployable artifact. At Auto Trader we’ve been moving to containerised deployments using Docker. By adding a final task to the Airflow DAG to make a Git commit (simply updating the path on S3 where the most recent MLeap model is located), a deployment can be triggered.
Using Docker, the container is built by fetching the MLeap model from S3, building and testing the app, and finally publishing it to a container registry. It’s important to note that, once the model has been fetched, this build process is the same as the majority of our apps.
A note on testing strategy
Before we discuss how the container is deployed, just a quick note on testing strategy. You’ll notice a stage in the deployment pipeline above where we test the service, running both unit tests and integration tests. Running unit tests is straightforward and doesn’t differ from any other web service application. Integration tests, though, present a bit of a problem, since the output from the model changes with each training iteration. We can easily check if the service is returning a response that conforms to the correct schema. But how do we know if the numbers themselves are correct?
To solve this problem, during the model training stage, we write some test data out alongside the model itself. This test data contains both the inputs to the model and the returned prediction for a sample of vehicles. Then, when it comes to running integration tests, we can use this test data as the input to the service, and check that the output matches the saved predictions.

Deployment using Kubernetes
With our application and model packaged together as a Docker image, the final piece of the puzzle is to deploy it. At Auto Trader we’re in the process of moving all our deployments to Kubernetes. Kubernetes is a system for automating the deployment of containerised applications, giving us a bunch of useful features including automatic load balancing, scaling, health checks and monitoring.
Because our build artifact is a standard Docker image, our app is deployed using Kubernetes in exactly the same way as any other web app. Publishing the Docker image to the container registry is enough to trigger a deployment to both our pre-production and production environments following Continuous Deployment.
Summary
Our approach of using Databricks notebooks for model discovery, Airflow and Spark for model training, and MLeap, Docker and Kubernetes for model deployment has worked well for us. A lot of this technology is new for us, in particular, we hadn’t used Spark to train a model for real-time predictions before. We’re pretty happy with how this turned out though. The process works reliably end-to-end without any manual intervention, and we’re confident that if something goes wrong during training, our data integrity checks will alert us and halt the deployment. As it stands, a data scientist can make a change to the model training Spark job, and after the model has retrained, the new model will be deployed to production in a matter of minutes.
Future work
Earlier this year, Databricks announced the MLFlow project, which aims to ease a number of pain-points in the machine learning lifecycle. Explicitly called out was a desire to make it easier to save ML models in a portable format, and serve them out in REST services. At the time of writing, MLFlow is making quick progress, so we’re watching closely to see whether it can be used to simplify this process.
Conference Talk
If you would like to hear us talk more on this subject, here is the talk that we gave at the Devoxx conference in May 2019.
Enjoyed that? Read some other posts.
Related Posts
19 Jun 2024—Stevie Woods and Philippa Main

Data underpins and helps to drive every part of Auto Trader’s business. With over half a million listed vehicles and 1.4 million visitors to Auto...
05 Apr 2024—Bethanie Garfin
Photo by Kenrick Baksh on Unsplash
At Auto Trader, the behavioural events we collect about our consumers are a core part of our data platform, fueling real-time personalisation on-site and reporting our core business KPIs. Because...
05 Oct 2023—Tim Summerton-Brier, Stevie Woods, John Harrison
Photo by Tico Mendoza
Back in April, Auto Trader gave a few of us the opportunity to attend Data Council 2023 in Austin, Texas, USA. Data Council is an independently curated conference that covers many aspects of working...
17 Apr 2023—Olivia Pennington & Tom Armitage
Photo by Nik Shuliahin on Unsplash.
You’ve done the hard work in researching, developing and finally deploying your shiny new Machine Learning (ML) model, but the work is not over yet. In fact it has only just...
24 Mar 2023—Tom Armitage & Olivia Pennington
Photo by Stephen Dawson on Unsplash.
Advertising packages are the core product at Auto Trader. Depending on the package tier our customers purchase, they get to appear in...
21 Jul 2022—Chris Gillatt
Photo by Markus Spiske on Unsplash
At Auto Trader, we keep our Kubernetes clusters up-to-date to the latest or T-1 version available in the Google Kubernetes Engine ‘stable’ release channel. We run large clusters (450+ workloads,...
