Dry running our data warehouse using BigQuery and dbt
In this post, we talk about how we use dbt & BigQuery dry run jobs to validate our 1000+ models in under 30 seconds.
As mentioned in a previous post, at Auto Trader, we use
dbt (data build tool) to transform data in BigQuery, our
cloud data warehouse. Ensuring the data in our platform is accurate and available on time is important for both
our internal and external data consumers. When we build a dbt project it compiles our models—templated select statements
which define the transformations to our underlying source data—into SQL that is executed against the data warehouse.
While dbt is an excellent tool for creating these complex transformation pipelines, it does not check that the select
statements are valid SQL. The current solution for this is a CI environment that executes your
project and runs data tests to check the transformations are working as expected. The main drawbacks of this are
speed and cost as the database engine you are using needs to execute SQL in a production-like environment.
Verifying the validity of dbt SQL
Currently, analysts and engineers contribute to a single dbt repository. Any additions and changes are validated by a pull request and
local compilation, which outputs the SQL select statements that dbt will run when building your data. These SQL statements
can be copied into the BigQuery console and tested against our preprod or prod environments to check for SQL validity.
When a SQL statement is entered in the console, BigQuery will quickly sense check your query using what is known as a dry run. This query returns no data but is fast (<1 second), free and crucially a very reliable indicator on whether your query will run for real.
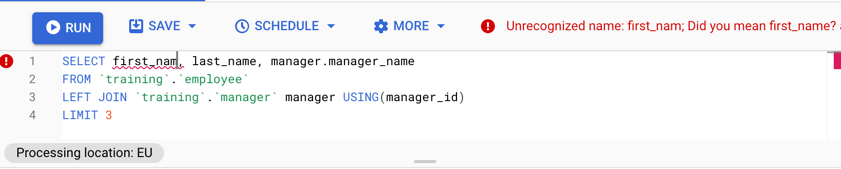 This query has a typo in one of the column names which results in a dry run failure
This query has a typo in one of the column names which results in a dry run failure
 With the typo fixed, the dry run is successful. We can be confident our query will run
With the typo fixed, the dry run is successful. We can be confident our query will run
Dry running SQL using the Python API
We can use the BigQuery client libraries to dry run SQL queries and verify that we have written valid BigQuery SQL. The snippet below shows how to do this in Python:
from google.api_core.exceptions import BadRequest
from google.cloud.bigquery import Client, QueryJobConfig
from pprint import pprint
JOB_CONFIG = QueryJobConfig(dry_run=True, use_query_cache=False)
def dry_run_sql(client: Client, sql: str):
try:
query_job = client.query(sql, job_config=JOB_CONFIG)
print("Query will result in schema:")
pprint(query_job.schema)
except BadRequest as e:
print(f"Query will fail with errors:\n {[err['message'] for err in e.errors]}")
client = Client()
valid_sql = """
select first_name, age
FROM (select "anne" as `first_name`, 34 as `age`)
"""
invalid_sql = """
select first_nam, age
FROM (select "anne" as `first_name`, 34 as `age`)
"""
print("Output of first query:")
dry_run_sql(client, valid_sql)
print("Output of second query:")
dry_run_sql(client, invalid_sql)
Which when run outputs:
Output of first query:
Query will result in schema:
[SchemaField('first_name', 'STRING', 'NULLABLE', None, (), None),
SchemaField('age', 'INTEGER', 'NULLABLE', None, (), None)]
Output of second query:
Query will fail with errors:
['Unrecognized name: first_nam; Did you mean first_name? at [2:8]']
Here we dry run two queries. The first is valid SQL, and the dry run outputs the resultant schema of the query without
actually running it. By printing query_job.schema, we can see that our query results in two columns called first_name
and age, with types STRING and INTEGER respectively. The second query contains a typo which results in a
helpful error message indicating the problem—the schema is not available in this case.
The manifest
When you compile your dbt project it produces an artefact called the manifest. It is a JSON file containing all the
information about your project’s resources such as model configuration, metadata and—importantly for this application—the compiled SQL of the model. Here is a reduced snippet of a dbt manifest with just the nodes attribute:
{
"nodes": {
"model.my_project.my_test_view": {
"resource_type": "model",
"depends_on": {
"macros": [],
"nodes": [
"model.my_project.my_staging_model"
]
},
"config": {
"materialized": "view",
"on_schema_change": "ignore",
},
"database": "at-example-project",
"schema": "training",
"unique_id": "model.my_project.my_test_view",
"compiled_sql": "select * FROM `at-example-project.training.my_staging_model`"
},
"model.my_project.my_staging_model": {
...
}
}
}
Naively we could take our project’s manifest, loop through each model and dry run the compiled_sql against our
production environment. Following on from the previous snippet this would look something like this:
import json
# manifest.json is created from running `dbt compile`
# against the preprod or production environment
with open("manifest.json") as f:
manifest = json.load(f)
for node_key, node in manifest["nodes"].items():
node_sql = node.get("compiled_sql")
if node_sql:
dry_run_sql(client, node_sql)
Running this outputs the predicted schema on success, or an error message on failure of each node. However, if we want to incorporate this into validating that any changes to a dbt project will succeed, we need to take into account model references.
Referencing other models
A dbt model can reference another model using the ref macro, which is the key to building more complicated transformations on top of your source data. When a model reference is compiled by dbt it is replaced with the relation name for your project’s target database and environment. For example:
-- my_test_view
select *
FROM {{ ref('my_staging_model') }}
-- Compiles to
select *
FROM `at-example-project.training.my_staging_model`
When a model references another model, it creates a dependency. This means that if B references A, we must
run A before B. Otherwise, the SQL will fail or give out of date results. When dbt runs it figures out the correct order
by constructing a directed acyclic graph (DAG).
Verifying code changes in CI/CD
Let’s say an engineer wishes to add some new models that reference existing models in the production environment, like so:
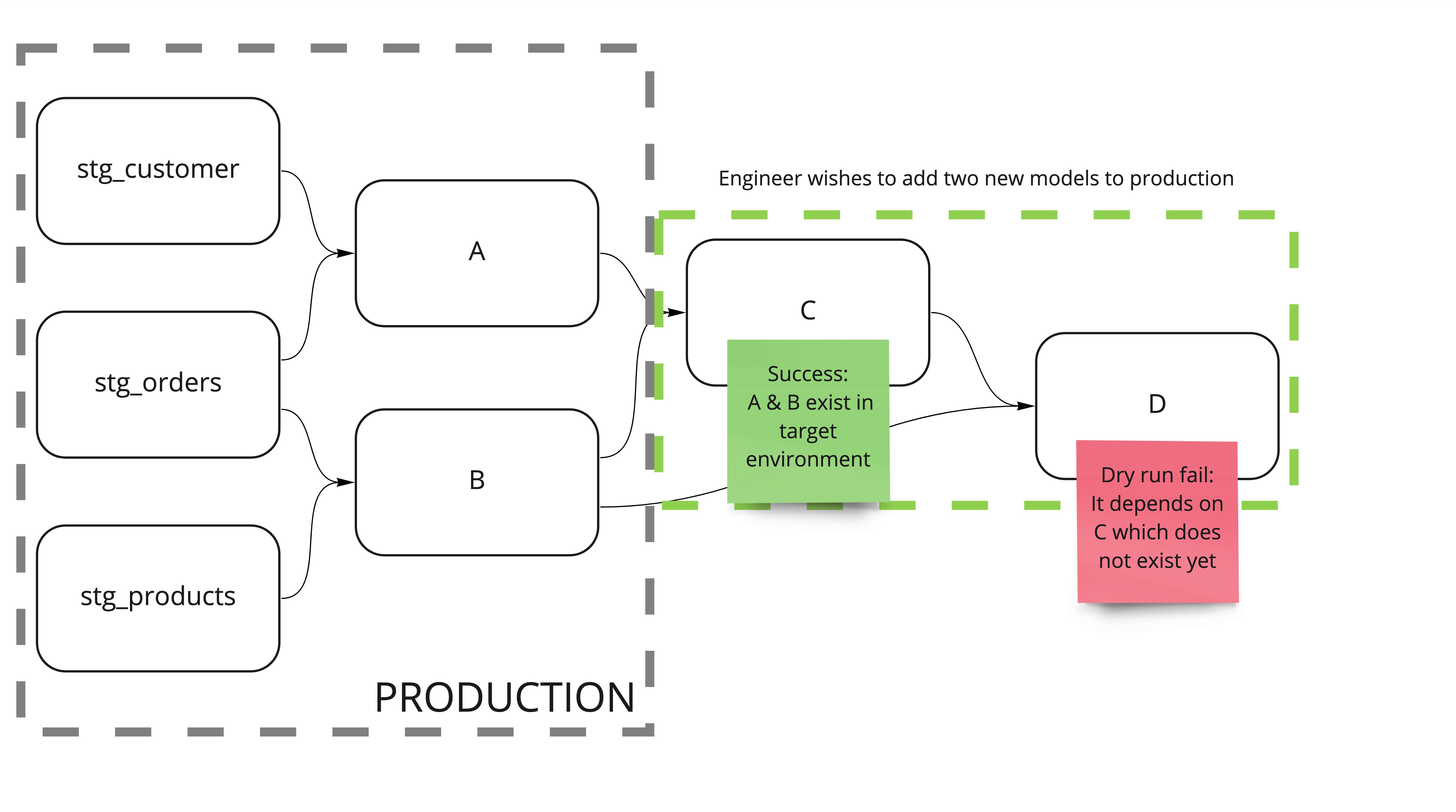 C & D are new models that an engineer wishes to be included in our nightly data warehouse update
C & D are new models that an engineer wishes to be included in our nightly data warehouse update
If we were to compile the dbt project against the production environment and naively dry run the compiled_sql then
we would see a not found error when dry running model D:
google.api_core.exceptions.NotFound: 404 POST Not found:
Table at-example-project.training.C was not found
This is because C is a new model and has not run in production yet. We could fix this by creating C in production
but that is no longer a dry run and this could have unintended side effects. To solve this we needed a way of replacing
the reference to the model with something equivalent to that table without modifying the production environment.
Replacing references with select literals
We can get around this problem by using the query_job.schema from before to construct a select statement that is
syntactically equivalent to the model we are referencing:
-- my_test_view
select *
FROM {{ ref('my_staging_model') }}
-- Compiles to
select *
FROM `at-example-project.training.my_staging_model`
-- Replace with a select literal and dry run this
select *
-- built from query_job.schema of upstream dry run
FROM (select "any_string" as `first_name`, 42 as `age`)
This requires us to dry run each model in the correct order so that for each model we are testing,
we know all the schemas of the upstream models and can replace their references with select literals. These literals
can become very complicated, and our actual implementation can handle struct datatypes and repeated columns.
For sources, we can keep the reference unchanged as the source table is managed outside of dbt and
should exist in the target environment. We handle seeds by reading the seed file and inferring the appropriate
select literal from the CSV headers and column datatypes. As of dbt 0.21.0, we also have to handle the on_schema_change
configuration for incremental models. For these models, the schema returned by the dry run is not necessarily the
schema of the model after dbt has run. Models can be configured to ignore new columns which means that the select literal
should be based on the existing incremental schema in the target environment.
Wrapping up
We have been using our implementation of dbt dry run in CI/CD for a few months now and it has given us much more
confidence in our overnight data warehouse run. The dry run can catch typos and SQL syntax errors, such as typing selec
instead of select, which would otherwise be compiled by dbt without error until the overnight run failed. It has also been valuable
in ensuring that schema changes made by different teams will not break downstream transformations.
We have decided to open source the dry runner in the hope that other members of the dbt community can use it to find errors in their dbt projects before they reach production.
Enjoyed that? Read some other posts.
Related Posts
19 Jun 2024—Stevie Woods and Philippa Main

Data underpins and helps to drive every part of Auto Trader’s business. With over half a million listed vehicles and 1.4 million visitors to Auto...
05 Oct 2023—Tim Summerton-Brier, Stevie Woods, John Harrison
Photo by Tico Mendoza
Back in April, Auto Trader gave a few of us the opportunity to attend Data Council 2023 in Austin, Texas, USA. Data Council is an independently curated conference that covers many aspects of working...
23 Nov 2022—Connor Charles, Andrew Crosby, Jason Motee, Michael Reppion, Olivia Pennington
Photo by Markus Quinten de Graaf on Unsplash
Here at Auto Trader, we aim to help customers find their perfect vehicle as quickly and easily as possible. But with over 400k vehicles advertised onsite at any one...
