Auto-generating an Airflow DAG using the dbt manifest
This post explores our continuing effort to improve our developer experience and ability to respond to incidents. Here, we discuss how we made scheduling dbt tasks simpler and more transparent, removing the need for the dbt user to consider scheduling when deploying a new model.
Auto Trader uses dbt (data build tool) to process and refine raw data in BigQuery, our cloud data warehouse. Dbt runs dbt models, custom templated SQL defined by us, to build and populate tables and views in BigQuery. It can manage the dependency between models, deciding which order to run them.
We use Apache Airflow to schedule and orchestrate our data pipelines and were already using Airflow to kick off a daily run of dbt early in the morning. Airflow allows us to ensure our upstream requirements are satisfied before running the dbt models by using sensors. This makes sure we only attempt to process raw data when it is available in BigQuery.
Scheduling dbt to run
To schedule dbt models, we need to tell Airflow which models to run. Initially, we had a single task to run all models. Dbt is, after all, designed to determine the hierarchy of tasks and run them in the most optimal manner, running models concurrently where possible.
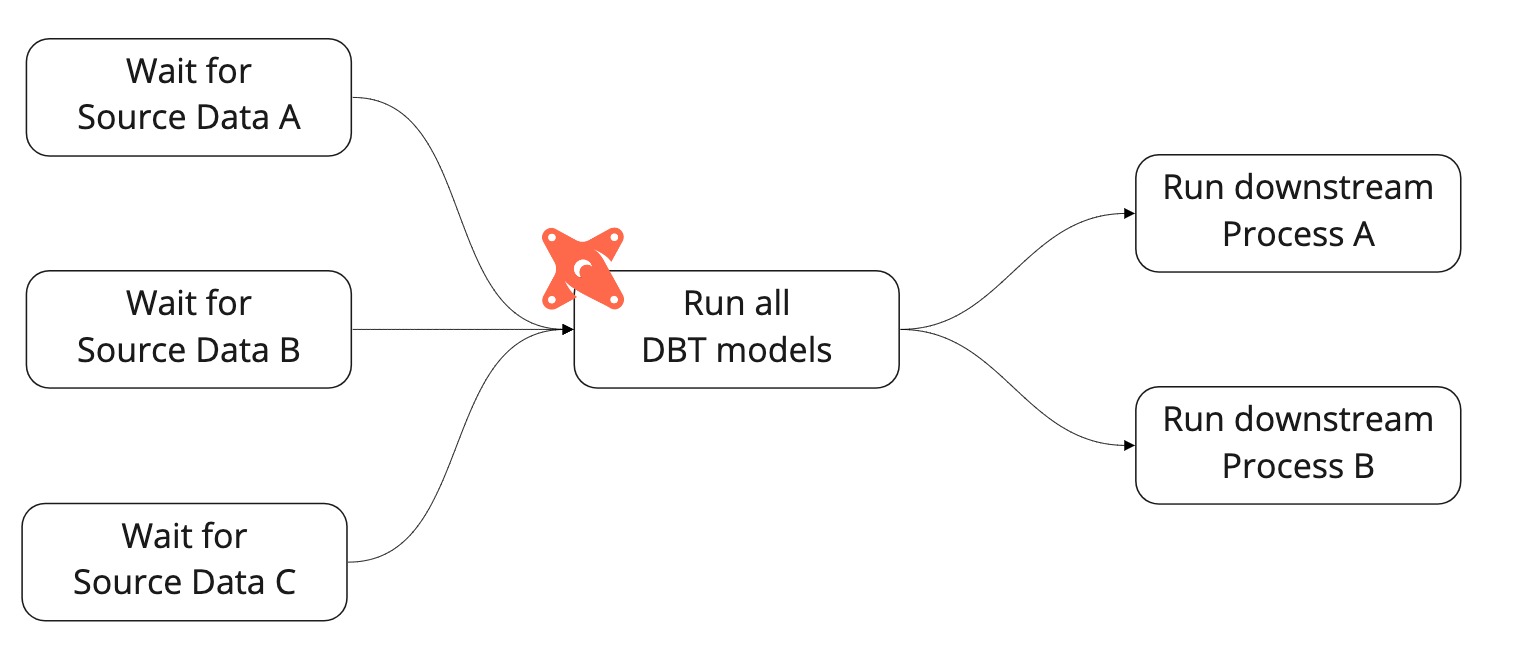
This setup presented us with a problem. When there was an error with a single model, we would get an alert stating “DBT FAILED” and we would have to dig through the logs to understand which model had failed. Once the underlying issue was fixed, we would have to restart the whole dbt process, which resulted in some expensive and time-consuming models being re-run unnecessarily. Similarly, from Airflow’s perspective, we had no separation of dbt models. This meant that all dbt models had to wait for all source data to become available before running. Additionally, all downstream processes would always have to wait for all dbt models to complete successfully before running. This resulted in unnecessary delays to data availability, which became more problematic as we scaled up our use of dbt.
Separating out groups of models within Airflow
We decided to move some responsibility for scheduling model runs from dbt to Airflow. We split dbt models into logical groups and manually configured Airflow to run each group. Dbt was responsible for managing the hierarchy within each group, but Airflow managed the hierarchy of the groups themselves.
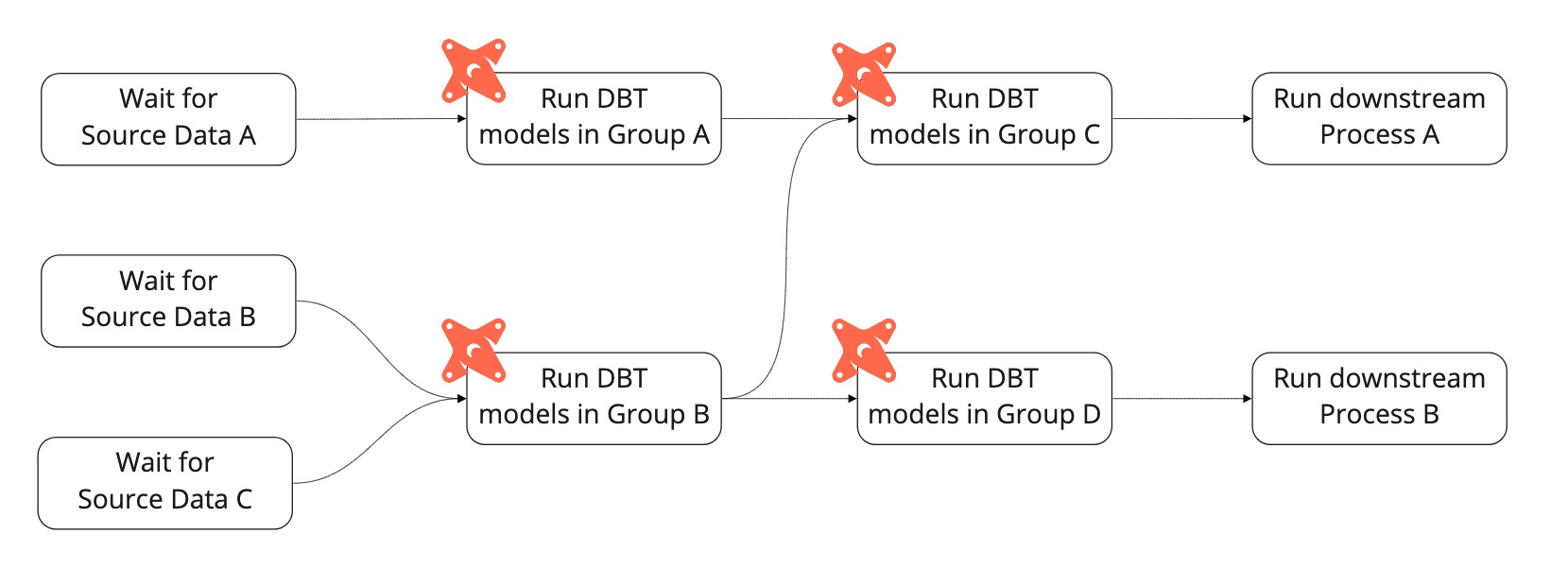
This provided us with some separation and initially worked quite well. We were able to see which task groups had succeeded and which had failed. The dbt task groups only had to wait for the relevant upstream data sources to become available before running, rather than waiting for every single source to become available. Downstream processes only had to wait for the relevant task group to complete before starting, rather than waiting for the entire dbt process.
Ultimately, this solution became very complicated. As the number of models and their interdependency increased, so did the complexity of their scheduling. Developers who wanted to update dbt models were also required to update the scheduling and manage the upstream and downstream dependencies. This often led to mistakes caused by human error, where a sensor would be missed or a task added to the wrong group. Situations like this would cause a model to run earlier than it should, resulting in bad data that required manual intervention to fix.
Separating out each dbt model in Airflow
Inspired by this blog post, we sought to delegate the full responsibility of scheduling model runs to Airflow.
By splitting out every single dbt model into individual Airflow tasks, we do not need to manage “groups” of dbt models. In turn, this allows us to auto-generate the Airflow workflow so that developers only need to worry about creating the dbt models. Updating the scheduling system happens automatically.
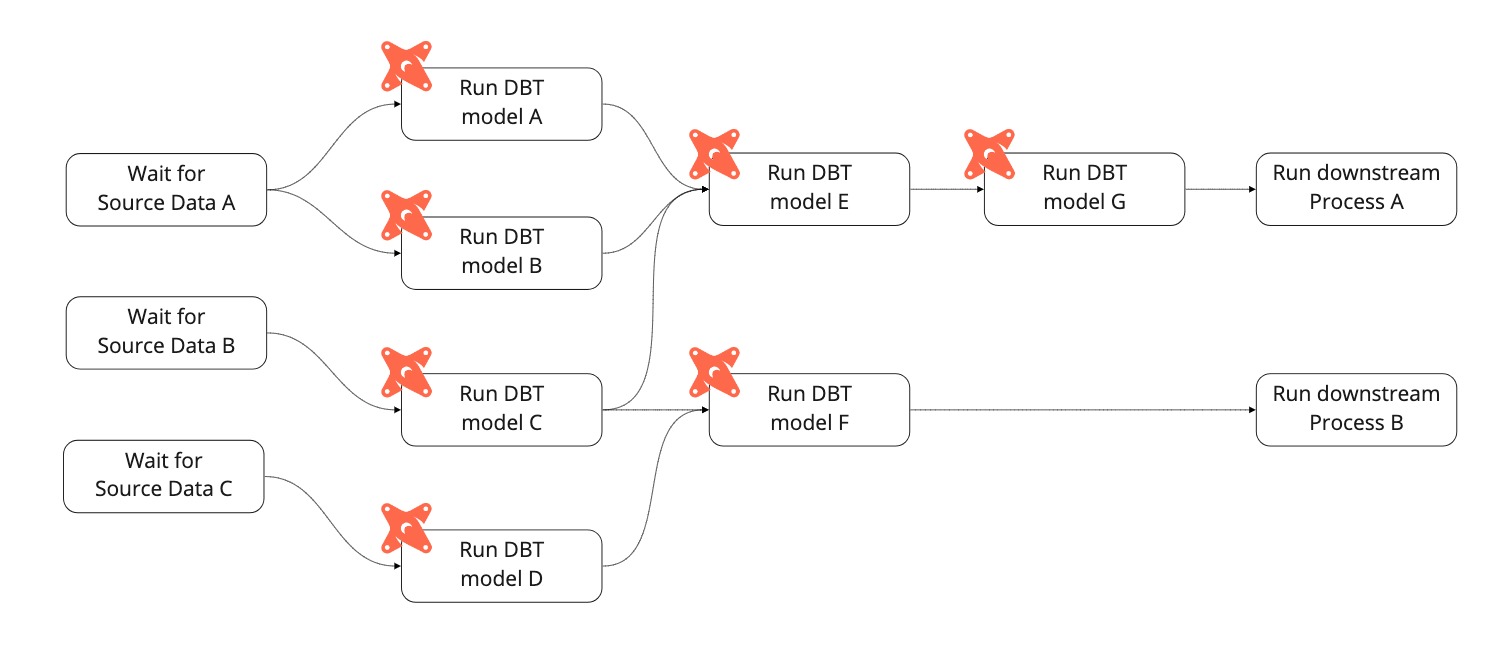
When dbt compiles, it generates a manifest file containing information about all models and their hierarchy. Our deployment pipeline creates this manifest file as part of the build and passes it to Airflow, which uses it to dynamically generate tasks to run the dbt models.
We have over 1000 dbt models, a mixture of tables1, incrementals2, views3 and ephemerals4. We additionally have over 200 sources5.
We wanted to create an Airflow task for each dbt table, incremental and view model, in the right order so that no model would be run until all of its upstream dependencies had been run. We did not want to create a task for ephemerals or sources (as these are not dbt models in their own right), or for disabled models.
Making the manifest available to Airflow
While the blog post that gave us inspiration helped get us started, we needed to understand how it could fit within our own ecosystem. In particular, how it fitted in with our deployment pipelines and how dbt could share its manifest file with Airflow.
We considered various solutions:
- using a common file location that our pipeline could write to and Airflow could read from
- setting an Airflow variable (similar to an environment variable but stored in Airflow’s database)
- committing to our Airflow repo and triggering a build
- publishing it to our artefact repository
- too many others to mention!
We decided not to publish the manifest to our artefact repository or any other version-controlled store. Because various teams add models frequently, we did not wish to store another pointless history, as our dbt project is already version-controlled.
We also felt that embedding the file into our Airflow build would be slow and cumbersome, and add a lot of time rebuilding and deploying Airflow. It also mixed Airflow and dbt concerns, which could cause dbt issues if we ever needed to roll back some Airflow changes.
In the end, we felt that the best solution was to use our continuous deployment pipeline to set an Airflow variable. This variable consists of a cut-down version of the manifest, containing only the objects that we need.
We created a custom plugin in our Airflow deployment which exposes an endpoint that accepts the cut-down manifest file via a PUT request. This stores the manifest as an Airflow Variable which can be used to dynamically generate the dbt workflow in Airflow.
It’s important to state that there are some shortcomings to this. The size of the manifest means we need to strip it down to be able to send it via a PUT request and store it in a variable. We are also concerned that the Airflow code has to continuously parse the manifest which could become slow. It seems to work just fine for now and our concerns may be unfounded, but we’re keeping an eye on it regardless!
We don’t think we’ve found the right long-term solution, but what we have works for now and is a step in the right direction.
How we did it in code
Thinking about creating an Airflow task to run each model, we realised that not all dbt models need to be run explicitly. Ephemeral models are absorbed, when dbt is compiled, into the models that reference them. Therefore, we needed to create a task to run each model that dbt would persist as a database table or view: table, incremental and view. We started by creating a DbtTaskGenerator class that walks the dbt manifest building a tree of persisted models, creates a task to run each of them and chains them together so that upstream models are always run before their downstream models. The code to do this is shown below.
Once you have this basic code, you can enhance and adapt it to suit your own needs. For instance, we added an enhancement to replace dbt sources with sensors to check that the expected source data is present, via a look-up table of source model name -> sensor. Some teams may want to add an enhancement to run seed models if they use those.
Basic DbtTaskGenerator source
The task generator:
import logging
from copy import copy
from logging import Logger
from typing import Dict, List, Optional
from airflow import DAG
from airflow.models import Variable, BaseOperator
from airflow.operators.dummy_operator import DummyOperator
logger = logging.getLogger(__name__)
class DbtNode:
def __init__(self, full_name: str, children: List[str], config: Optional[dict]):
self.full_name = full_name
self.children = children
self.is_model = self.full_name.startswith('model')
self.name = self.full_name.split('.')[-1]
self.is_persisted = self.is_model and config["materialized"] in ['table', 'incremental', 'view']
class DbtTaskGenerator:
def __init__(
self, dag: DAG, manifest: dict
) -> None:
self.dag: DAG = dag
self.manifest = manifest
self.persisted_node_map: Dict[str, DbtNode] = self._get_persisted_parent_to_child_map()
self.logger: Logger = logging.getLogger(__name__)
def _get_persisted_parent_to_child_map(self) -> Dict[str, DbtNode]:
node_info = self.manifest['nodes']
parent_to_child_map = self.manifest['child_map']
all_nodes: Dict[str, DbtNode] = {
node_name: DbtNode(
full_name=node_name,
children=children,
config=node_info.get(node_name, {}).get('config')
)
for node_name, children in parent_to_child_map.items()
}
persisted_nodes = {
node.full_name: DbtNode(
full_name=node.full_name,
children=self._get_persisted_children(node, all_nodes),
config=node_info.get(node_name, {}).get('config')
)
for node_name, node in all_nodes.items()
if node.is_persisted and node.full_name
}
return persisted_nodes
@classmethod
def _get_persisted_children(cls, node: DbtNode, all_nodes: Dict[str, DbtNode]) -> List[str]:
persisted_children = []
for child_key in node.children:
child_node = all_nodes[child_key]
if child_node.is_persisted:
persisted_children.append(child_key)
else:
persisted_children += cls._get_persisted_children(child_node, all_nodes)
return persisted_children
def add_all_tasks(self) -> None:
nodes_to_add: Dict[str, DbtNode] = {}
for node in self.persisted_node_map:
included_node = copy(self.persisted_node_map[node])
included_children = []
for child in self.persisted_node_map[node].children:
included_children.append(child)
included_node.children = included_children
nodes_to_add[node] = included_node
self._add_tasks(nodes_to_add)
def _add_tasks(self, nodes_to_add: Dict[str, DbtNode]) -> None:
dbt_model_tasks = self._create_dbt_run_model_tasks(nodes_to_add)
self.logger.info(f'{len(dbt_model_tasks)} tasks created for models')
for parent_node in nodes_to_add.values():
if parent_node.is_model:
self._add_model_dependencies(dbt_model_tasks, parent_node)
def _create_dbt_run_model_tasks(self, nodes_to_add: Dict[str, DbtNode]) -> Dict[str, BaseOperator]:
dbt_docker_image_details = Variable.get("docker_dbt-data-platform", deserialize_json=True)
dbt_model_tasks: Dict[str, BaseOperator] = {
node.full_name: self._create_dbt_run_task(node.name)
for node in nodes_to_add.values()
if node.is_model
}
return dbt_model_tasks
def _create_dbt_run_task(self, model_name: str) -> BaseOperator:
# This is where you create a task to run the model - see
# https://docs.getdbt.com/docs/running-a-dbt-project/running-dbt-in-production#using-airflow
# We pass the run date into our models: f'dbt run --models={model_name} --vars '{"run_date":""}'
return DummyOperator(dag=self.dag, task_id=model_name, run_date='')
@staticmethod
def _add_model_dependencies(dbt_model_tasks: Dict[str, BaseOperator], parent_node: DbtNode) -> None:
for child_key in parent_node.children:
child = dbt_model_tasks.get(child_key)
if child:
dbt_model_tasks[parent_node.full_name] >> child
To call the task generator:
from datetime import datetime
from airflow import DAG
from dbt_task_generator import DbtTaskGenerator
dag = DAG(
dag_id="dbt_connected_task_creator_test_dag",
start_date=datetime(2019, 1, 1),
schedule_interval="0 1 * * *",
)
dbt_task_generator = DbtTaskGenerator(dag, manifest)
dbt_task_generator.add_all_tasks()
Summary
By connecting our dbt release pipeline to a custom Airflow endpoint, we are able to share our dbt structure on each dbt deployment. This allows Airflow to automatically separate out our dbt models into separate tasks, connecting source sensors as appropriate. We benefit from full visibility within Airflow of how our models have run and can run tasks at the earliest possible opportunity. We can also re-run exactly the models we want, without re-running other models.
Footnotes
-
A table is a model that drops and recreates the entire table each time the model is run. ↩
-
An incremental model makes inserts or updates to a table incrementally depending on when the model is run. ↩
-
A view is a model that creates data on the fly when required. It is materialised and can be accessed as if it were a physical table. ↩
-
An ephemeral model contains SQL sub-queries that are used by other types of models. The SQL is generated on the fly when used by other dbt models. It is not materialised into a physical table and cannot be accessed outside of dbt. ↩
-
A source is a physical table that can be referenced by dbt but is externally created and controlled. ↩
Enjoyed that? Read some other posts.
Related Posts
19 Jun 2024—Stevie Woods and Philippa Main

Data underpins and helps to drive every part of Auto Trader’s business. With over half a million listed vehicles and 1.4 million visitors to Auto...
05 Oct 2023—Tim Summerton-Brier, Stevie Woods, John Harrison
Photo by Tico Mendoza
Back in April, Auto Trader gave a few of us the opportunity to attend Data Council 2023 in Austin, Texas, USA. Data Council is an independently curated conference that covers many aspects of working...
23 Nov 2022—Connor Charles, Andrew Crosby, Jason Motee, Michael Reppion, Olivia Pennington
Photo by Markus Quinten de Graaf on Unsplash
Here at Auto Trader, we aim to help customers find their perfect vehicle as quickly and easily as possible. But with over 400k vehicles advertised onsite at any one...
