How Auto Trader ensures end-to-end data trust at scale
At Auto Trader, we make use of several tools to store and maintain our data. The majority of our analytical data is stored in BigQuery, a serverless cloud-hosted data warehouse. From here, we use dbt to transform and model that data.
Inevitably, things can go wrong with the tasks involved in building the datasets that our stakeholders rely on. We’re always looking for ways to automate and better operationalize our data workflows. We want to be confident in the quality of the data that we’re sharing, which is why it’s important to know when a dataset doesn’t look quite as we expect.
An important feature of our data pipelines is observability, as the complexity of data workflows can otherwise make it hard for us to investigate quality issues. To help with this, we’ve adopted Monte Carlo as a monitoring tool, which provides a rich UI to set up notifications and custom domain-specific checks on our data. In this post, we’ll explain how we have automated the creation of Monte Carlo notifications and embedded them into our existing data development process.
Importance of Data Observability
Countless issues can arise when running our batch processes in dbt, for example, changes in the underlying source schema, data delays, a spike/drop in row count, the list goes on… but unless it’s a breaking change, these issues can often slip under our radar. Hours later, these inconsistencies are usually spotted by an end consumer in a Looker dashboard or a customer-facing product.
Catching issues in the reporting layer not only leads to a lack of trust in our data, but it’s also a lot harder to clean up. The erroneous data has more than likely travelled through a series of downstream models. The longer it goes unnoticed, the bigger the blast radius and the more resources it requires to fix.
It’s impossible to manually check each of our datasets for inconsistencies every single day, costing us significant time and energy—not to mention frustration!

That’s where Monte Carlo (MC) comes in. We use MC to monitor the health of our data, as well as tracking and triaging incidents. Things break a lot, so our monitoring tools must be up to scratch! Better observability of our data can hopefully prevent incidents from trickling into our consumer reports or at the very least, catch them more quickly.
So What Is Monte Carlo?
Not to be confused with the Edwardian musical comedy, in short, Monte Carlo is a data observability platform. Among other things, Monte Carlo performs a series of standard out-of-the-box checks on data with automated, end-to-end machine learning across your data pipeline: from your cloud warehouse to the business intelligence layer. This includes tracking dimensions such as freshness, volume, and distribution. If one of these metrics falls outside an expected range, Monte Carlo helps us identify the root cause and anything downstream that might be affected, generating alerts for the relevant channels.
For example, if a model is usually refreshed daily and was last updated two days ago, Monte Carlo lets us know.
If one of our dbt models breaks, Monte Carlo would visualise its lineage, showing any impacted models across all of our data stack. This lets us manage incidents in Slack effectively, with the appropriate stakeholders being notified.
Benefits of Automation
The Monte Carlo UI is user-friendly and has everything we need to set up the notifications/monitors for our models living in BigQuery. But we wouldn’t be developers if we didn’t want to make our lives as simple as possible by automating as much as possible!

It’s not just about making our jobs easier; automating the process comes with some extra benefits:
- As they live in our dbt repository, each notification/monitor configuration is version-controlled by git.
- There’s now one less place where we need to make changes. The MC configuration can be added and committed at the same time as the model SQL.
- MC can be kept consistently up to date with the state of our codebase.
- MC gives us scope to enforce standards around minimum levels of monitoring for certain types of tables.
Creating Notifications In Monte Carlo
Monte Carlo makes it easy to add notifications on an individual table or dataset level. Once created, any breaches in the monitoring criteria will be forwarded to the channels specified.
The information needed:
Channel: The type of channel you want the notifications sent to (email, webhook, Slack). At Auto Trader we use Slack as the preferred channel for the majority of our alerting.Incidents: The type of incidents you want to be notified of. For our use case, we want all incidents types—the default option.Dataset/table locations: Our BigQuery structure contains datasets with tables that may be owned by different teams. Because of this, we opted to add the notifications at the more granular table level.SQL Rules & SLI: We’ll leave this feature for now.Slack channel: A list of Slack channels that we want the particular notifications to be forwarded.
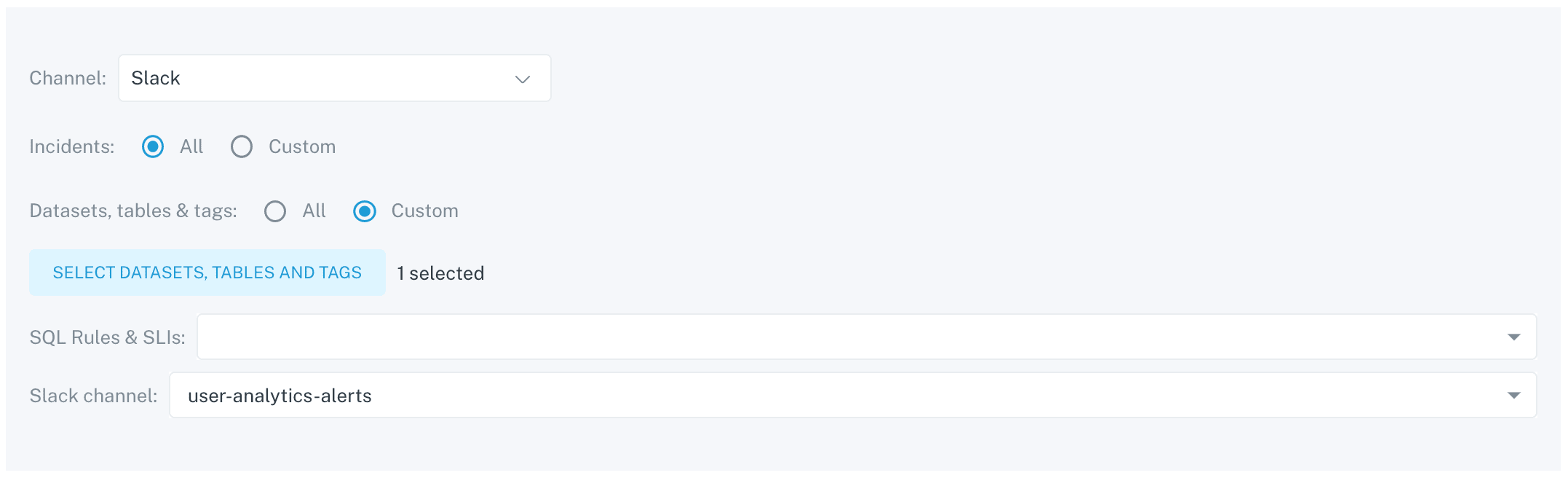
Out of the list above, the only details that vary are the table locations and Slack channel names. We specify these channels in our metadata in dbt.
DBT Model Properties
dbt allows you to declare a set of model properties in the form of .yml files. These properties give you the power to add detailed documentation and meta information about your models and their schema.
You can add custom key-value pairs to the meta property, describing any additional metadata outside of the generic descriptions and docs. Once added, the model properties are compiled into the dbt manifest, alongside the model definitions and lineage. The properties and meta fields are surfaced in the auto-generated dbt docs and can be made available to any service that has access to compile dbt.
We were already using the model properties and meta fields extensively in our existing DBT setup; for documentation, data governance (i.e. does the model contain PII data) and cataloguing. So it seemed like a no-brainer to add additional metadata around observability.
Here’s an example of the model properties with notification channels specified:
models:
- name: page_views
description: Client side page view events
meta:
data_governance.team_owner: User Analytics
data_governance.has_pii: False
data_observability.notification_channels: [ "user-analytics-alerts" ]
columns:
- name: page_view_id
description: Unique page view identifier
We added an array of Slack channel names to a custom data_observability.notification_channels meta field. That means that all the details needed to construct a notification are available when we compile the JSON manifest.
The Monte Carlo API
The Monte Carlo API is exposed via GraphQL, a query language that lets you define types for your data. You provide an ID and secret token to let MC know who you are, along with a query for the data you’re looking for. We use several queries for different things, such as getting existing notifications, creating or updating them, and deleting them.
Here’s an example that is a mutation, meaning it’s modifying server-side data (in this case a notification):
mutation {
createOrUpdateNotificationSetting(
notificationType: "slack_v2"
#! The Slack channel ID we want to forward alerts to
recipient: "C01JMTLBUKS"
rules: {
#! List of tables that will overwrite existing tables for a notification
fullTableIds: "at-data-platform-prod:stg_snowplow.email_leads"
}
#! Notification uuid - this will only be provided if the notification already exists
settingId: "0c11ec9c-0ac5-4770-af50-ec14692afac5"
) {
notificationSetting {
createdBy {
firstName
lastName
}
recipientDisplayName
routingRules {
tableRules
}
}
}
}
Here we would be providing a Slack channel ID and a table name, telling Monte Carlo to update the notification settings for that channel if they already exist, or create a new notification if they don’t. You can see we are also supplying the creator of the notification and any additional table rules.
This is how we translate between our code and what Monte Carlo understands, with other queries having a similar structure.
Bringing it all together
So far, we’ve described the components needed to integrate MC into our dbt project. We can clearly define which models require notifications and where to forward them in the model properties. We can also create and update MC components using their GraphQL API.
Now we need to automate and tie these two pieces together. We do this using a Python script to perform the following steps:
- Parse the JSON manifest: The first stage in our script is to parse the JSON manifest and mould it into a suitable structure for MC. The grain of notifications in MC is on a per-channel basis, whereas the metadata we have defined is on a per-table basis. We pivot and group the dictionary by channel, returning a dictionary with
key = channel name,value = list. - Get Monte Carlo’s current state: To avoid repeatedly adding the same notifications every day, we pull the existing list of notifications from MC. We define our own MC client using the Python GraphQL library GQL.
-
Compare notification states: We then compare the state of notification in our dbt project vs what already exists in MC and assign each notification to one of 3 categories:
CREATE: If a new channel is present in our metadata but doesn’t have a corresponding notification in MCUPDATE: If the channel already exists in MC but there is a change to the list of table names. Tables are removed from a notification when they exist in MC but not in the metadata.DELETE: If a notification channel in MC is no longer present in our metadata
We define these categories using a Python
enum. Notifications that don’t fulfil the above criteria are discarded as their state hasn’t changed since the last sync. - Synchronise changes with Monte Carlo: Once we’ve decided on the action to take for each notification, we iterate through them and make a POST request to the MC API to perform the said action.
- Scheduling: The majority of our tables are updated daily, the workflow of which is handled by the scheduling tool, Airflow. It seemed logical to schedule Monte Carlo at the same frequency with Airflow.
Conclusion
We’ve covered a lot of stuff here, from why we care about our data, to the nitty-gritty of how we integrate with various frameworks and tools. Monte Carlo in particular has let us improve our data observability, maintaining trust in our data for our stakeholders.
Hopefully, this has given you some insight into what goes on in software development at Auto Trader, and the benefits that automation can bring to the workplace.
Enjoyed that? Read some other posts.
Related Posts
19 Jun 2024—Stevie Woods and Philippa Main

Data underpins and helps to drive every part of Auto Trader’s business. With over half a million listed vehicles and 1.4 million visitors to Auto...
05 Apr 2024—Bethanie Garfin
Photo by Kenrick Baksh on Unsplash
At Auto Trader, the behavioural events we collect about our consumers are a core part of our data platform, fueling real-time personalisation on-site and reporting our core business KPIs. Because...
