Improving confidence in our tracking with auto-generated Snowplow types

Photo by Kenrick Baksh on Unsplash
At Auto Trader, the behavioural events we collect about our consumers are a core part of our data platform, fueling real-time personalisation on-site and reporting our core business KPIs. Because of this, we must ensure trust and confidence in the data we track. In this post, I will describe our recent improvements to integrate strong typing through auto-generated Snowplow types into our platform tracking capabilities.
Our first iteration of Snowplow
When consumers visit Auto Trader, we track each interaction they make—for example, viewing a page or making a vehicle reservation—by sending an event to Snowplow, our behavioural tracking platform. The structure of these events is defined using self-describing JSON schemas; once tracked, each event goes through a validation process, comparing the data sent to the relevant schema. Invalid events, for example, if a property is the wrong type, are removed from the enrichment process. Unless a large-scale incident occurs, we consider these events non-recoverable, excluding them from any downstream data modelling.
Here’s an example of one of our schemas:
{
"description": "Advert",
"properties": {
"id": {
"description": "The advert ID",
"type": ["string"],
"maxLength": 50
},
"make": {
"description": "The make of the vehicle",
"type": ["null", "string"],
"maxLength": 40
},
"vehicle_category": {
"description": "The category of the vehicle being advertised",
"type": ["null", "string"],
"enum": ["bike", "car", "van"],
"maxLength": 20
}
},
"additionalProperties": false,
"type": "object",
"required": ["id"],
"self": {
"vendor": "uk.co.test",
"name": "advert",
"format": "jsonschema",
"version": "1-0-0"
},
"$schema": "http://iglucentral.com/schemas/com.snowplowanalytics.self-desc/schema/jsonschema/1-0-0#"
}
Since adopting Snowplow, we have built a suite of JavaScript libraries to provide tracking capabilities to our micro frontend applications. These libraries give a layer of abstraction around the Snowplow tracker, only exposing a set of track functions and hiding responsibilities like tracker initialisation, consent management, and, most importantly to this post, mapping data to the correct event structure.
Historically, the Snowplow schemas were also abstracted away from the frontend. Applications would pass an unstructured loosely typed object and the library would do the rest, conditionally mapping the data to the correct schemas based on the attributes provided.
Here’s an example of what that function looked like:
const trackEvent = (data: {[key: string]: string | number | boolean | undefined | Array<string>}) => {
const entities = []
if (data.advertId) {
entities.push({
schema: 'iglu:uk.co.test/advert/jsonschema/1-0-0',
data: {
id: data.advertId,
make: data.make,
model: data.vehicle_category
}
})
}
if (data.retailer) {
// build retailer entity
}
// track event with entities
}
Lessons learnt
The approach above came from a need to support two tracking platforms while we migrated to Snowplow from its predecessor Google Analytics (GA). Although abstraction of the core tracking implementation is beneficial, giving us control and consistent tracking configuration, we’ve learnt that hiding the event construction creates a few pain points:
- Scalability: Mapping unstructured data is easy to maintain when there are simple events and a few attributes. However, we now have 132 schemas and the conditional statement required quickly becomes unmanageable and hard to scale.
- Lack of Control: We design our schemas so that events are composable. However, abstracting the event creation into a single place leads us to a one-size-fits-all approach, taking control and flexibility away from the event producer.
- Schema Violations: The loose typing of the data provided by our frontend applications means that we have little compile-time validation of the data; if an event is sent with a missing field or a value of the wrong type, we find out at run-time, usually in production, when the data is already lost.
Auto-generating schema types
To tackle some of these pain points, we wanted to create a new TypeScript library containing strongly typed representations of our JSON schemas that could be used by our frontend applications and integrated into our tracking capabilities. We also wanted the generation of this library to be automated to prevent additional overhead when creating/amending schemas and to avoid divergence between the JSON schemas and their respective types.
To build this library, we use json-schema-to-typescript, which, with some post-process tweaking, converts the Snowplow JSON schemas into TypeScript interfaces.
We decided to include all schema versions in our library to simplify new schema rollouts and to decouple the version of our library from the introduction of breaking schema changes.
As a result, the interfaces follow a {schemaName}{versionWithoutHyphens} naming convention.
The advert JSON schema above would be converted to the following interface:
export interface Advert100 {
SCHEMA_KEY: "Advert100";
/**
* The advert ID
*/
id: string;
/**
* The make of the vehicle
*/
make?: null | string;
/**
* The category of the vehicle being advertised
*/
vehicle_category: ("bike" | "car" | "van");
}
Integrating these interfaces into the rest of our tracking guarantees that all schema properties are of the correct type, a valid enum value and included if required. However, this doesn’t mean that we’re immune to schema violations. We’ve covered most constraints, but there are some that we can’t represent easily, for example, minimum and maximum string lengths. These are inherently run-time data quality issues which are much harder to control.
Enforcing event structure
In the Advert100 interface definition, you might be wondering why we need SCHEMA_KEY.
Each event is broken down into two schema types—event and entities—where a self-describing event has a single event schema and zero or more entity schemas.
Adding a unique literal SCHEMA_KEY to each interface allows TypeScript to perform a discriminated union, which we use to create typed representations of the two schema types.
Here’s a simplified example of what those union types look like:
export type Event = Interaction100 | Appearance100
export type Entity = (Advert100 | Advert101 | User100 | SearchFilters100)
The advert schema shared at the start is an entity, but it doesn’t contain any reference to its type, so how do we determine what type each schema is?
In addition to self-describing JSON schemas, Snowplow Data Structures allow meta-data to be attached to each schema, including a schemaType, which we use to categorise schemas and construct the super types.
Integrating the types
Going back to our original trackEvent function, we can update the method signature and replace the unstructured data parameter with our generated types:
const trackEvent = (event: Event, entities: Entity[]) => {
const mappedEntities = entities.map(mapEntityToSelfDescribingStructure)
const mappedEvent = mapEntityToSelfDescribingStructure(event)
tracker.core.track(buildSelfDescribingEvent({ event: mappedEvent }), mappedEntities)
}
Enforcing this structure has multiple benefits: it gives us a clear tracking API, re-enforces the Snowplow event structure, improves the development experience and gives us smarter auto-completion.
Here is a basic example of how an app might use trackEvent:
const advertEntity: Advert100 = {
SCHEMA_KEY: "Advert100",
id: "advert_1",
make: "ford",
vehicle_category: "van"
}
const interactionEvent: Interaction100 = {
SCHEMA_KEY: "Interaction100",
label: "reserve vehicle"
}
trackEvent(interactionEvent, [advertEntity])
Each event is now validated at compile-time while the tracking is implemented, ensuring that each schema is correctly typed and reducing the number of bad events that fail in production.
The Entity and Event types enforce the Snowplow event structure but give each application the control and flexibility to send any combination of entity schemas with an event.
Automating type generation
Our Snowplow schemas are version-controlled in GitHub, which we then publish to Iglu, Snowplow’s schema registry, in a GoCD pipeline using Snowplow’s Data Structures API. The Data Structures API allows us to automate our deployment process and type generation by providing a set of endpoints to retrieve, validate and deploy schemas.
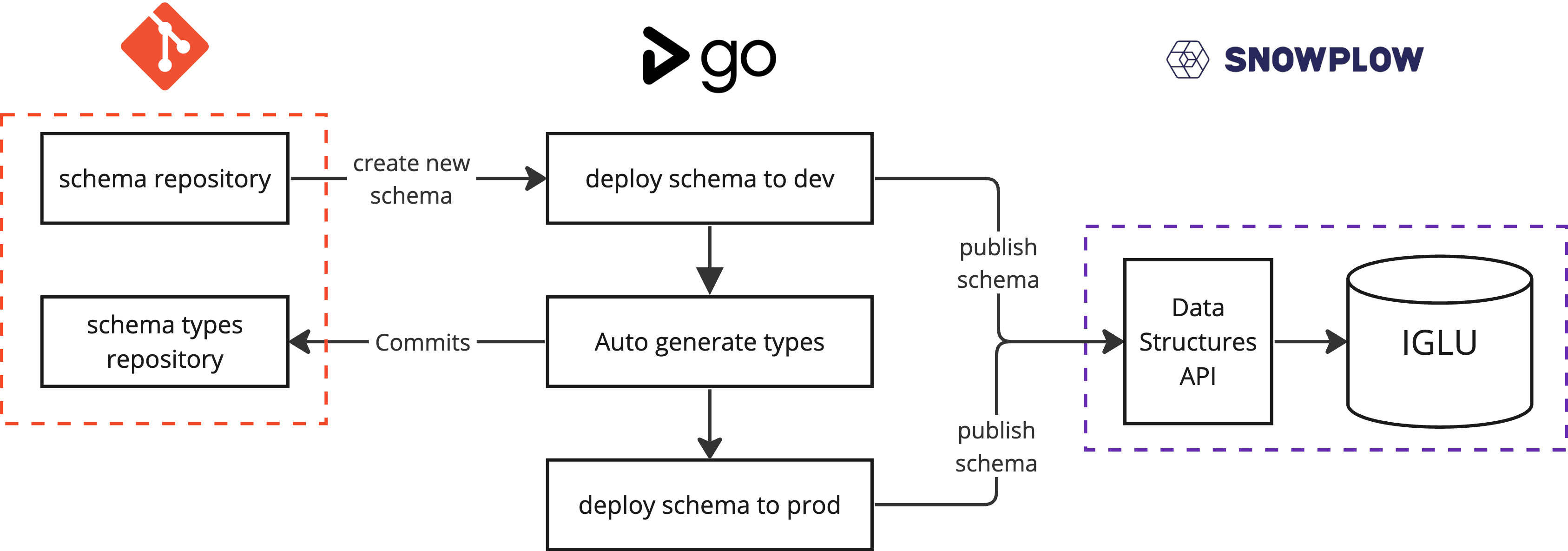
We decided to generate the types based on the development Iglu environment; this means we can test new schemas locally, make changes and overwrite (patch) versions in development before deploying them to production.
Summary
In summary, introducing TypeScript types to represent our Snowplow schemas has reduced the number of bad events we produce, giving us upfront validation and more control and flexibility over the events we send across Auto Trader.
We now have confidence that the data we track meets the JSON schema requirements. The next step is to ensure that the events meet our analytical requirements. We want to continue using the types to improve and extend our existing testing framework to validate the events against our tracking plan using Cypress end-to-end tests with Snowplow Micro.
Enjoyed that? Read some other posts.
Related Posts
19 Jun 2024—Stevie Woods and Philippa Main

Data underpins and helps to drive every part of Auto Trader’s business. With over half a million listed vehicles and 1.4 million visitors to Auto...
09 Jan 2024—Steven Morrow
Photo by Davide Ragusa on Unsplash.
In the late nineties and early noughties, every developer was adding a hit counter to their website. It essentially counted the number of page views...
17 Nov 2023—Catherine Wates
Photo by Pascal Meier on Unsplash.
At Auto Trader, we define landing pages as the first page a consumer sees when they enter our website. As you’d probably expect, the Auto Trader homepage is one of...
