Demystifying Large Language Models (LLM101)

Photo by Eugenio Mazzone on Unsplash.
Have you ever stumbled upon something that just completely captivated your attention? That was precisely what happened to me when I first came across Large Language Models (LLMs). It was during my preparation for interviews for my very first data science role and was learning about GPT-3. But my fascination grew exponentially when OpenAI released ChatGPT (GPT-3.5), and I am sure many fellow data scientists share this sentiment. Since then, I have been reading and learning more about them and I have also had the chance to apply them in practice and see their benefits firsthand, thanks to several projects I have worked on at Auto Trader. In this blog post, I will explain what an LLM is and how it works, and also share how we have been experimenting with Google’s LLM at Auto Trader.

The speed at which people become LLM experts. Source of image.
What is an LLM?
LLMs are powerful Deep Learning neural network models which are trained on huge amounts of text data and can predict what word comes next. They can help with Natural Language Processing (NLP) tasks, such as generating (writing a story from a prompt, answering customer questions), transforming (translating, changing the tone or format), summarising, and text analysing (finding out the sentiment, extracting the main topics).

OpenAI developed GPT-3 (Generative Pre-trained Transformer), but their GPT3.5 release brought LLMs to mainstream attention through their interactive ChatGPT interface. One of the key factors that boosted GPT3.5 performance was a technique called Reinforcement Learning from Human Feedback (RLHF). This technique allowed the LLM model to learn from its own mistakes and improve its outputs based on the ratings of human evaluators.
OpenAI recently released GPT-4, which has improved safety and insightfulness as well as the ability to handle multimodal inputs (accepting image and text inputs) emitting text outputs. However, Open AI is not the only player in the LLM field. Several other companies have also created and released their own LLMs, such as Google (LaMDA which powers their AI chatbot Bard, Palm, Gemma, and recently Gemini), Meta (LLaMA), Vicuna, Claude, Microsoft(Copilot), X(Grok) and Databricks (Dolly and recently DBRX). Some of these LLMs are open source, meaning that anyone can download and use them locally, depending on their computing resources. Others are available through APIs, such as Google Vertex AI’s Gemini, which is a cloud-based service that allows users to access LLMs for various purposes.
LLMs can provide new opportunities as well as challenges for researchers, practitioners, and enthusiasts. LLMs can offer powerful tools for enhancing communication, creativity, and productivity. But they also come with some challenges and risks that we need to be aware of, such as ethical, social, and technical issues. As LLM technologies grow quickly, it is critical to keep up with the latest developments. So do not be surprised if some of the information in this blog post is already outdated by the time you read it.
How do LLMs work in a nutshell?
Transformers are the essential architecture behind LLM models such as GPT-3.5, which use a Deep Neural Network with a key feature called the Attention Mechanism. The Attention Mechanism allows the model to focus on different parts of the input text, giving more weight to each word depending on its relevance. You can think of it as a spotlight that illuminates specific words, helping the model to pay more attention to important information. This ability to selectively concentrate on different elements helps transformers to understand complex language patterns, enabling them to produce coherent and contextually appropriate responses.
Transformer architectures consist of two parts, an encoder and a decoder. The encoder processes words from the input sentence, creating vectors that capture the context of each word. These vectors know where to focus thanks to the Attention mechanism. The decoder uses words from the input sentence, along with a start token1 (which signals the beginning of the sentence) and an end token (which signals the end of the sentence). It also takes the context vectors generated by the encoder as input. The decoder then generates words one by one. Starting with the start token, it generates the first word; with the start token and the first word, it generates the second word, and so on.
[1] A token is a piece of text that has been extracted from a larger sequence, often used as the basic building block for NLP tasks. Tokens are not split exactly where the words start or end - tokens can include trailing spaces and even sub-words. For example, in the sentence “The cat can’t sleep” the tokens are “The,” “cat,” “can”, “n’t” and “sleep”.↩
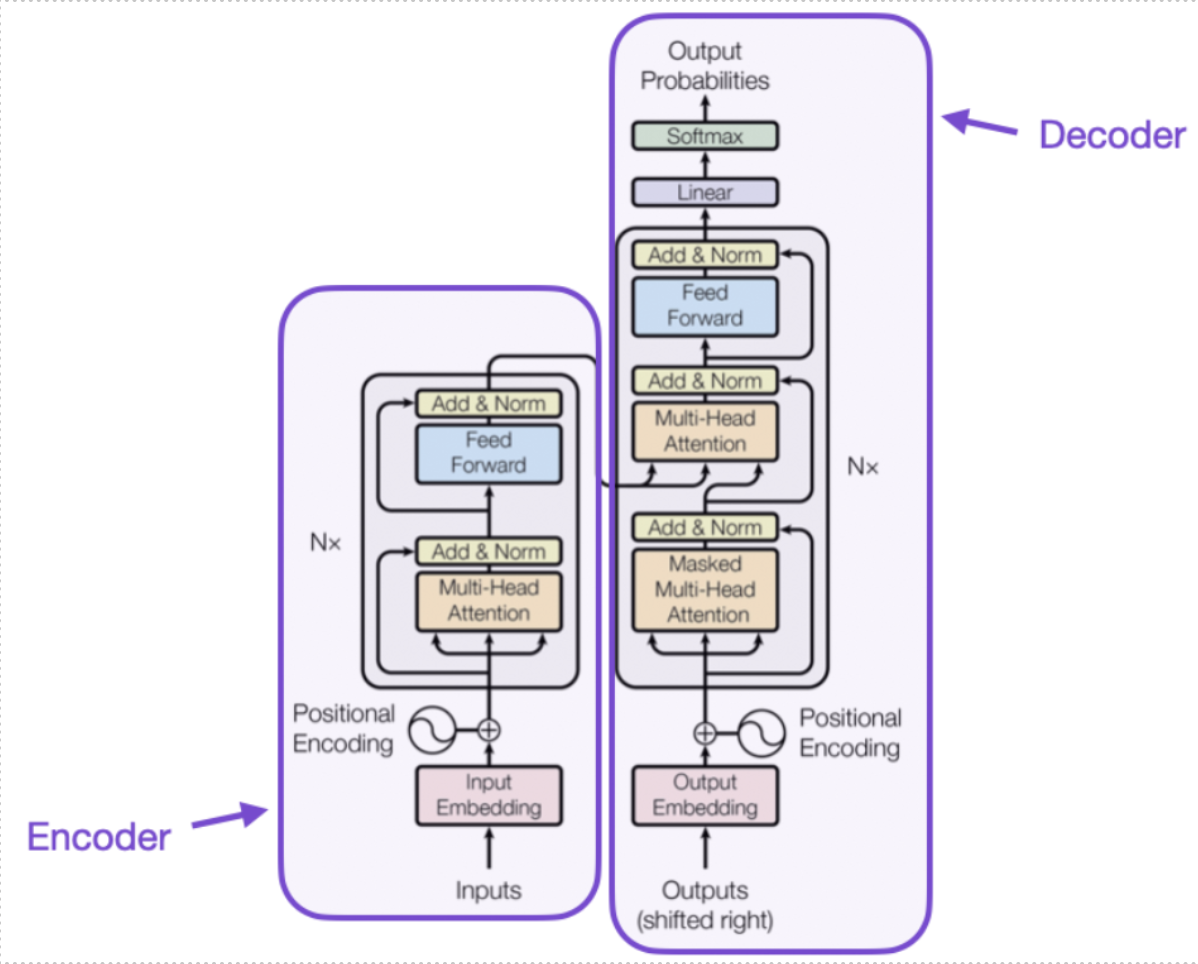
Transformer architectures taken from Attention Is All You Need paper published in December 2017.
LLMs sometimes suffer from hallucinations which can result in generating plausible but incorrect and inaccurate statements. Hallucinations can be controlled by adjusting a parameter called “Temperature” when generating texts. When generating text using an LLM, the decoder gives probabilities to each word in the vocabulary for the next word in the sequence. The Temperature parameter is used during the sampling process to adjust the probabilities before selecting the next word. Temperature regulates how creative or predictable the LLM is. A high temperature value (e.g., 0.8) makes the LLM more diverse and inventive, but also more prone to hallucinations. A low temperature value (e.g., 0.2) makes the LLM more consistent and reliable, but also more boring and repetitive.
Another way to reduce hallucinations is to use prompt engineering approach. Prompt engineering is a way of giving LLMs some hints or directions on what kind of text you want them to produce. For example, you can use keywords, questions, templates, or examples to guide the LLM towards your goal. By doing this, you can make the LLM more focused, accurate, and creative. Prompt engineering is not hard, but it requires some trial and error. You have to experiment with different prompts and see how the LLM responds. Sometimes, you might need to tweak the prompt or change the model parameters to get the desired output.
How to Use LLMs in Your Own Domains
I. Zero-Shot Prompting
One of the most common and basic types of prompt engineering is zero-shot prompting. This means asking a simple question or giving a simple instruction to an LLM, without providing any additional information or examples. This is mainly where an LLM may experience hallucinations.
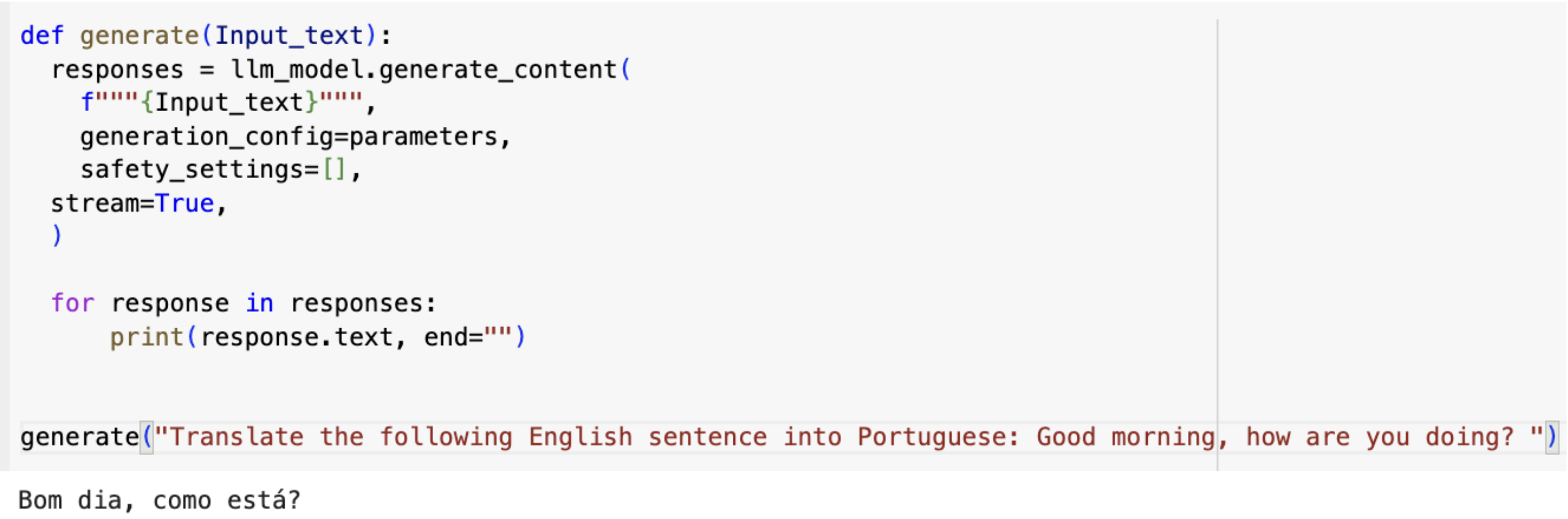
II. Few-Shot Prompting
Few-shot prompting, a type of in-context learning, is basically giving the LLM some context and direction, so it knows what you are looking for. You can do this by showing it some examples of the kind of answer you want, and then asking it to generate a similar one. This way, the LLM can learn from the examples and improve its answer.
For example, if you want the LLM to write a catchy product description for your product, you can show it some good product description from other products, and then ask it to write one for yours.

III. Fine-Tuning
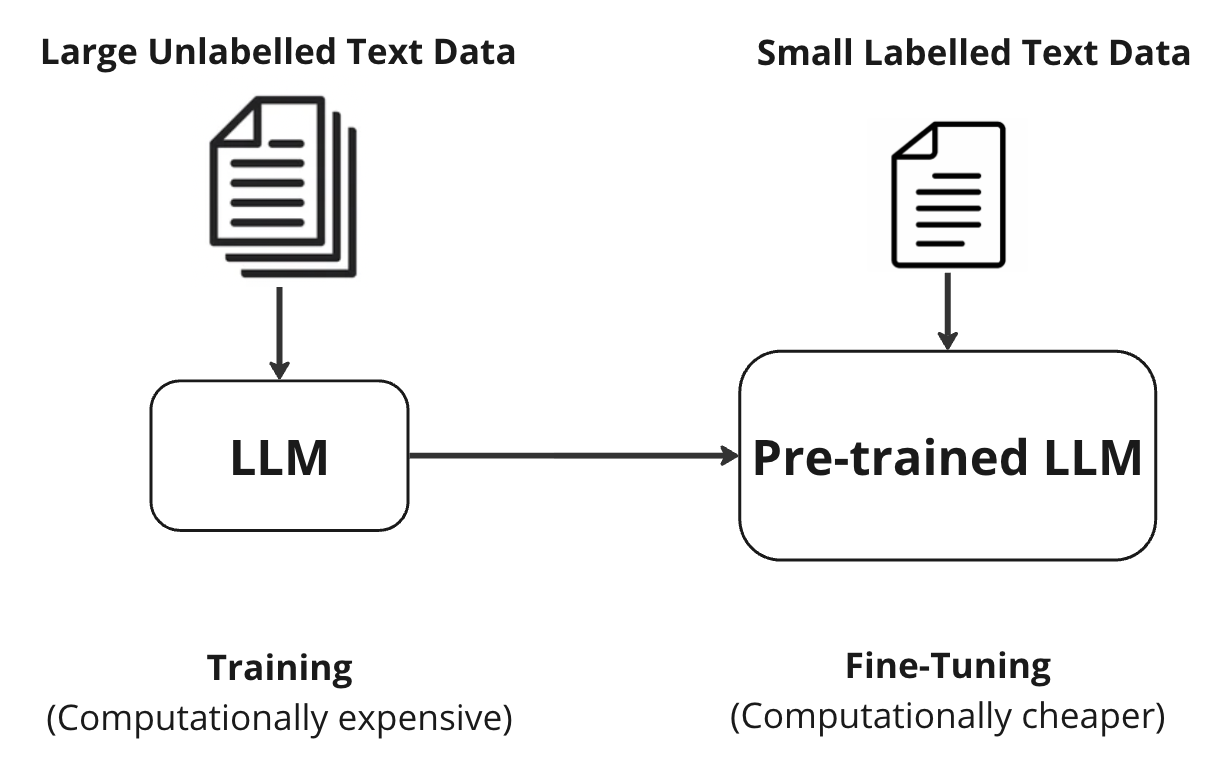
One might think why we cannot just make our own LLM for our specific purpose. Well, it is not that easy. LLMs need large amount of text data and powerful computational resources (such as GPUs or TPUs) to train. And, of course, one needs to know how to design their architecture, hyperparameters, and training methodologies to achieve desired performance. So, it requires the significant investment of time, resources, and expertise. However, there is an alternative approach: fine-tuning pre-trained LLMs.
Imagine you have a pre-trained LLM model that is like a super-smart student who has studied a lot of things from a huge library of books. Now you want to use this model for your own specific tasks. How can you do that? One way is to “fine-tune” the LLM model, which means you teach it some new things using a smaller and more relevant set of books. This way, the model can use what it already knows and adapt it to your tasks. Fine-tuning can be done on significantly small dataset and with small computational requirements.
There are two main ways to “fine-tune” a model, depending on what you want to achieve. One way is to use domain-specific fine-tuning, which means you show the model some books that are related to your topic or field. For example, if you want to use the model for medical tasks, you can fine-tune it with some medical books. The other way is to use task-specific fine-tuning, which means you ask the model to do some exercises that are related to your task. For example, if you want to use the model for text summarization, you can fine-tune it with some examples of summaries and their original texts. However, fine-tuning a LLM model in this way can also make it forget some of the things it learned before and reduce its overall capabilities. So, you must be careful and choose the right way to fine-tune your model depending on your goals and needs.
IV. Retrieval Augmented Generation (RAG)
RAG and fine-tuning are two different ways of incorporating your confidential/private text data into a LLM model. RAG is a technology that combines information retrieval and text generation to enhance the quality of generated content. In simple terms, it is a system which can fetch relevant information and pass that through the prompt to an LLM and then generate the response.
In a marketplace context, if you want to write a product description using RAG, the system can first look for some useful details from a database, such as customer reviews or seller ratings, and then use them to generate a more accurate and context-aware description. This approach helps in producing more informed and coherent responses by leveraging existing information. However, RAG is not perfect. Sometimes, the LLM might not understand the information from the database correctly and produce wrong or misleading texts.
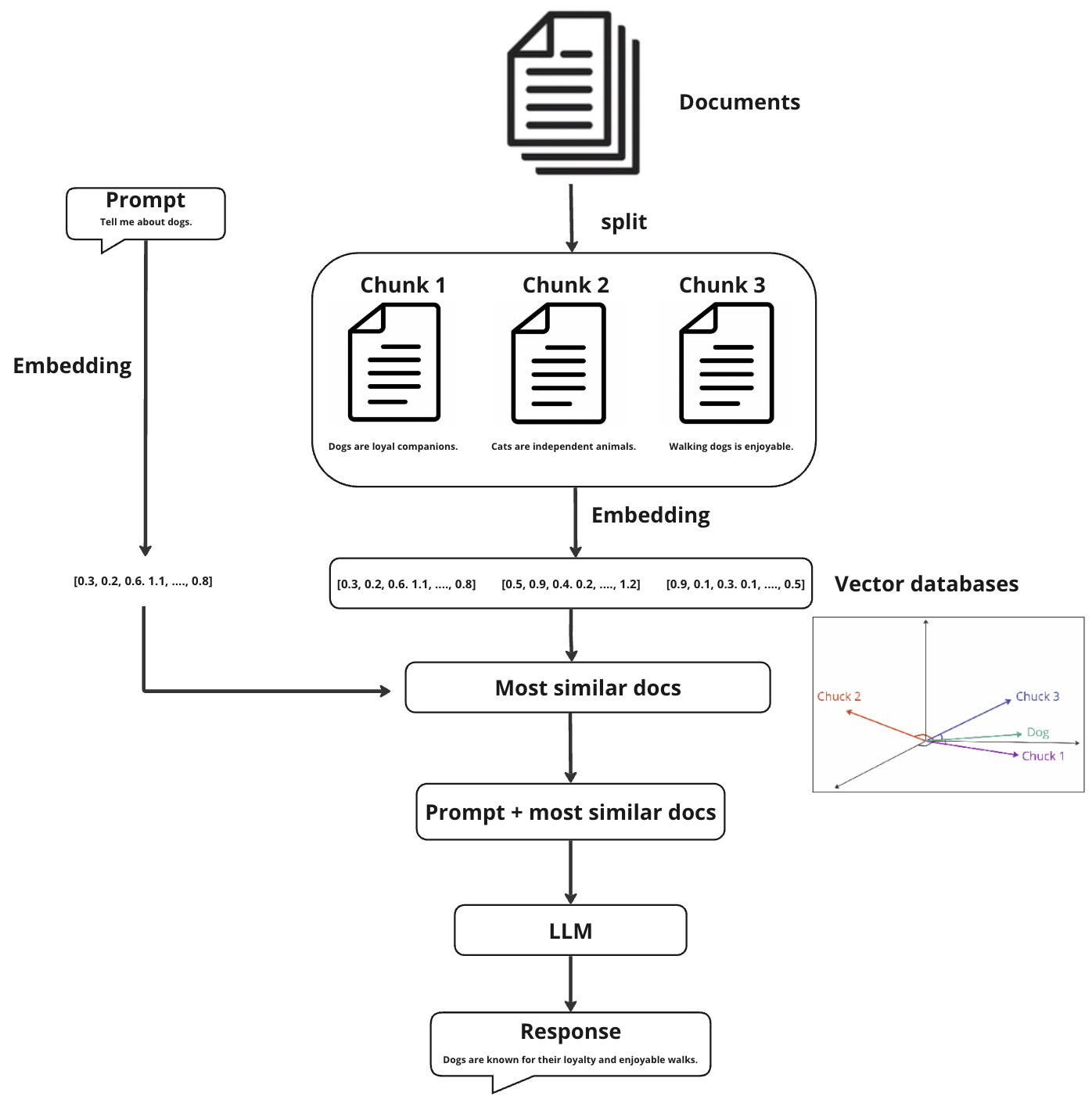
Schematic diagram of RAG. Created by author.
How to evaluate an LLM’s output?
Evaluating LLM performance and quality is inherently a challenging task and also a quickly evolving field of research. But how can one assess LLM quality and performance in lack of ground truth, or the “correct” answer? Unlike Machine Learning models whose performance can be easily measured using by various evaluation metrics for classification or regression problems, LLM models strive to generate new and previously unseen results. In some cases where there is a ground truth for an LLM task, such as translation, summarization, or text generation with a specific format or style, we can use metrics like BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) to evaluate their performance. BLEU is designed to measure semantic similarity and ROUGE measures overlap between output and reference texts. Recently LLM judges were introduced. They are a special kind of LLM model that can check and verify the results of other LLM models. Some research has shown that LLM judges can be remarkably effective in fact-checking. But we still need to be careful, because both the LLM and the judge might hallucinate together.
Google LLM (Gemini) through Vertex AI
At Auto Trader, we started by experimenting with some open-source LLMs, such as Bloomz-3B, LLaMA-v2–7B, and Dolly-7B. These models are relatively small in size and easy to use locally. However, we soon found out that they could not meet our expectations in terms of quality and consistency. We needed a more robust and reliable solution for our needs. That’s why we decided to use Google LLM (Gemini), which is one of the most advanced and comprehensive LLMs available today
All of Google’s cloud services are available under one roof with Vertex AI, a single artificial intelligence platform. With Vertex AI, one can quickly build machine learning models, train them and deploy them. Gemini is accessible through Vertex AI API.
Here is an example of employing RAG and Gemini in a question/answering the Vertex AI platform’s Search & Conversation, which was fed by content and text from https://help.autotrader.co.uk/ and www.autotrader.co.uk/content/.
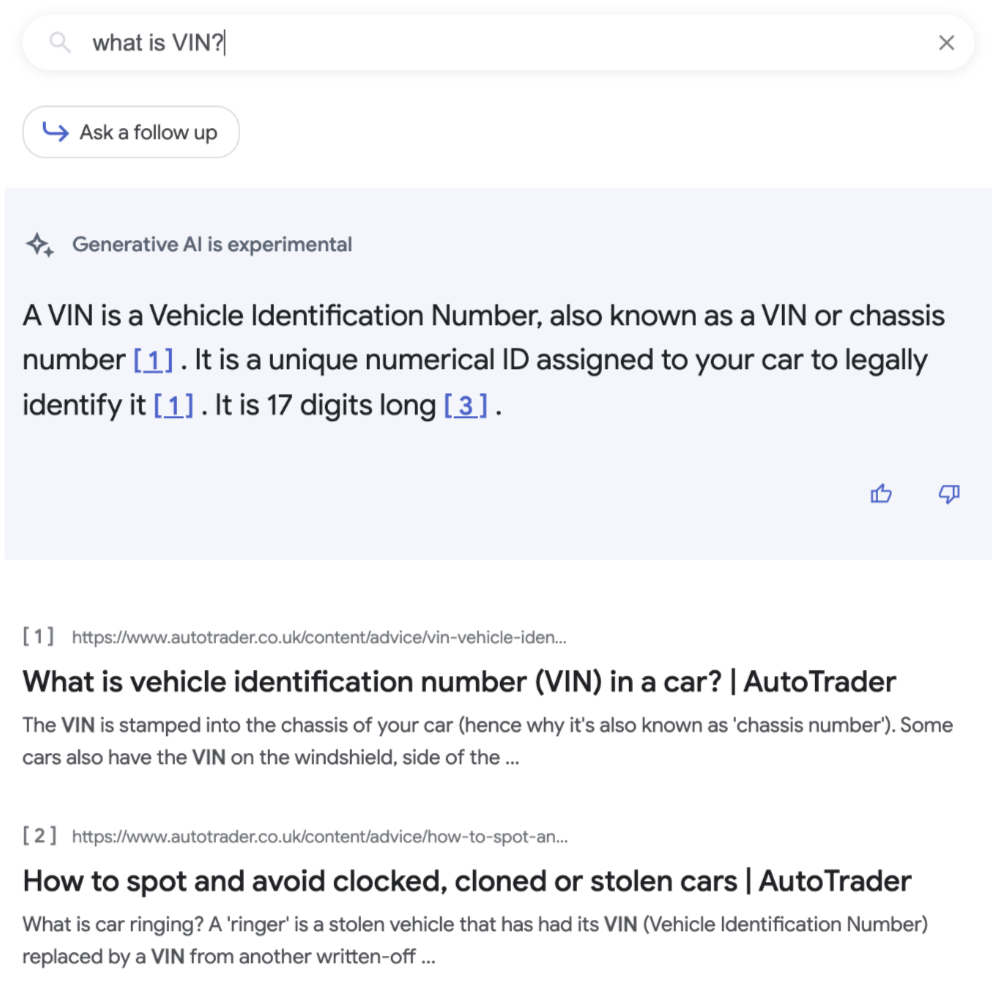
In another project we were exploring the idea of creating a chatbot that could answer questions about our engineering blog posts. We used Gemini API, Chroma DB and Langchain. We fed the text of all our engineering blog posts and then asked it some questions. We were impressed by the quality of the answers, but we also encountered some interesting situations. For example, once it answered us a correct answer but in German, even though we asked in English. This can be a general issue with LLMs which were trained on several languages, and this issue could be solved by indicating in the prompt to answer only in English.
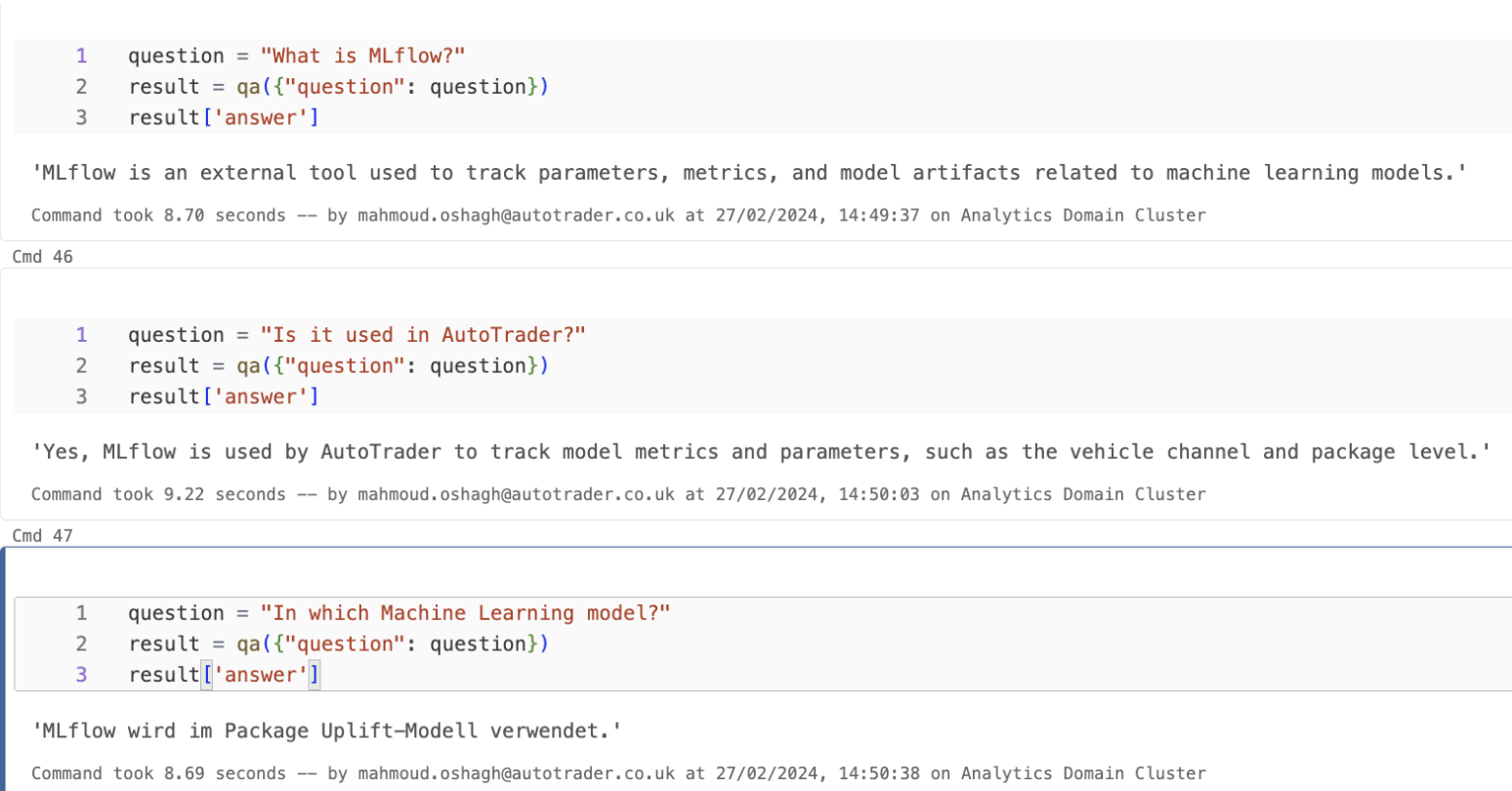
In another project, we wanted to better understand the main topics that were covered in the advert descriptions written for Auto Trader. We decided to use an LLM to extract topics for us. We had some predefined topics that we were interested in, and we wanted to see which ones were discussed in each advertisement. We asked Gemini to return a python list with the same length as the predefined topic list, “Identify which of these items “predefined topics” were explicitly mentioned in “advert_text” “. However, we needed more guidance to avoid generating extra text and information. One issue we noticed with this approach was that our predefined list was too long, and it always returned 0 values for the last items of the list. Our prompt was within the token limit of Gemini1.0 (8192), but we thought that having a very long prompt led to forgetting the context, which was the advert description at the beginning of our prompt. To overcome this issue, we decided to query Gemini for each topic separately, using the Vertex API. However, this solution was not scalable or cost-effective because of the high number of Vertex API calls.
In this blog post, I gave a short overview of what LLMs are, how they work, and how one can use them for various tasks. As I mentioned earlier, this field of research is evolving rapidly, so the information and models I shared here may soon become outdated. But it also shows how much potential, interest and investment there is in this topic from many companies. At Auto Trader, we are also interested in exploring the possibilities that LLMs can offer for an online Automotive Marketplace, such as better understanding customer support conversations, rating dealers based on their reviews, providing personalized recommendations using the RAG approach, or even generating content such as advert descriptions.
Enjoyed that? Read some other posts.
Related Posts
15 Aug 2024—Tom Armitage & Dustin Hayden
Image source: Wikimedia Commons.
The Bayesian approach to A/B testing has many advantages over a Frequentist approach. However, there are some drawbacks. This post discusses these challenges and our attempts to overcome them.
14 Aug 2024—Tom Armitage & Dustin Hayden
Image source: Wikimedia Commons.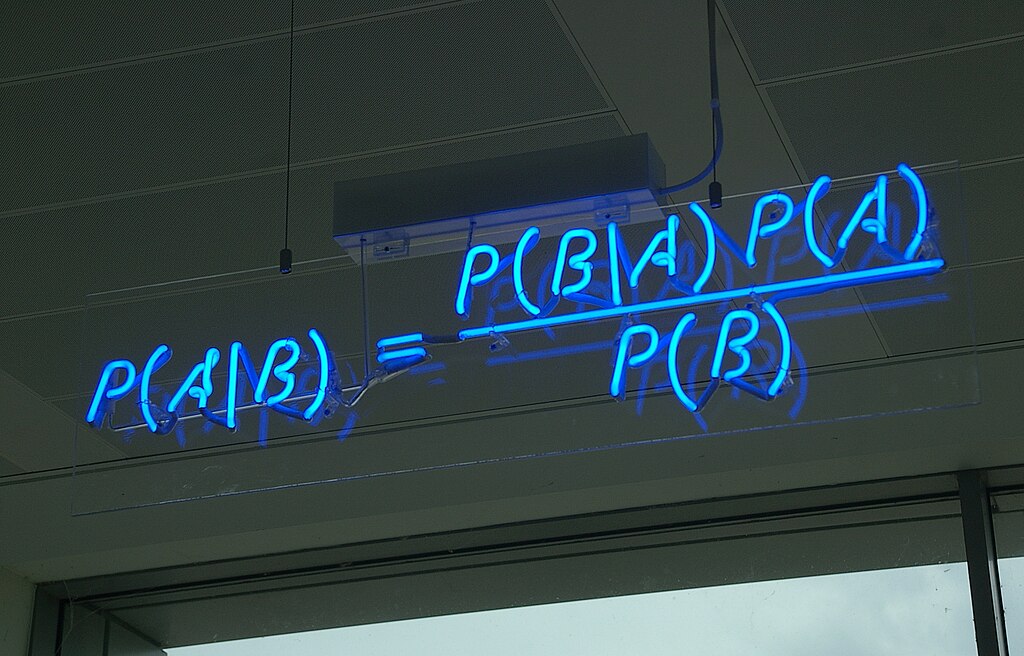
Websites are constantly changing. Here at Auto Trader, we use A/B testing to monitor the impact these changes have on the user’s experience. Fundamentally, we need to gather sufficient evidence to make a decision...
31 May 2024—Tom Armitage & Tom Kelly
Image source: Wikimedia Commons.
There has been great advancement in recent years in the field of image classification. With pre-trained models readily available and mature libraries making the process of developing and training your own models easy, you...
05 Oct 2023—Tim Summerton-Brier, Stevie Woods, John Harrison
Photo by Tico Mendoza
Back in April, Auto Trader gave a few of us the opportunity to attend Data Council 2023 in Austin, Texas, USA. Data Council is an independently curated conference that covers many aspects of working...
17 Apr 2023—Olivia Pennington & Tom Armitage
Photo by Nik Shuliahin on Unsplash.
You’ve done the hard work in researching, developing and finally deploying your shiny new Machine Learning (ML) model, but the work is not over yet. In fact it has only just...
24 Mar 2023—Tom Armitage & Olivia Pennington
Photo by Stephen Dawson on Unsplash.
Advertising packages are the core product at Auto Trader. Depending on the package tier our customers purchase, they get to appear in...

{kind=link}
{kind=link}
{kind=link}